
With PET·2000 shown to be a useful resource when taken as directed, the next step is to expand the system. As noted above several times, with 2000 words the process of lexical acquisition has hardly begun. The PET·2000 interface can be easily extended to additional word lists and corpora that can take learners on to higher levels of lexical acquisition. What word lists, and which corpora?
A preliminary adjustment at the 2000 level is to replace the PET (Hindmarsh, 1980) word list of 2387 words with West's (1953) more widely used General Service List (GSL) of 2000 words. The two lists are largely coextensive, except that the Hindmarsh list contains some surplus Anglicisms ("byro" and "duvet") and a quirky selection of phrasal verbs ("put up" but not "put up with"). Also, Nation's program of research uses West's list, so replacing the PET list with the GSL will bring PET·2000 into line with that agenda. Both lists antedate computing, of course, and are likely to be modified in the near future (the COBUILD list?), but as Nation (1994, p. 284) writes, the GSL "for all its imperfections has not yet been improved upon."
It was once thought that when a learner knew 2000 words, 80% of tokens in an English text, direct instruction in vocabulary should end; the rest could be acquired by inference. I myself expressed such a view in a recent conference paper (Cobb, 1995a, p. 5):
The advantages seem obvious of having control over 80% of the words of a text you might be trying to read in a foreign language. One is that if 80% of its words are familiar, you can probably work out the meaning of the rest for yourself.
I now disagree with this position, possibly as a result of working with students who more or less know 2000 words and watching them struggle with thick economics textbooks. When 2000 words was an impossible dream, it seemed adequate; once attained, it seems a bare beginning.
Knowing 80% of the words in a text still leaves 2 in 10 words unknown, a density probably too great for many successful inferences to take place. Here is a sentence about forestry in New Zealand with unknown words represented by gaps (the reader's skill in supplying the missing word will predict roughly a learner's success in inferring a meaning):
If _____ planting rates are _____ with planting _____ satisfied in each _____ and the forests milled at the earliest opportunity, the _____ wood supplies could further increase to about 36 million _____ meters _____ in the period 2001-2015. (Nation, 1990, p. 242.)
With seven words unknown in 40 (roughly 20%), it would appear that little successful inferencing can take place. Admittedly the sentence is out of context, but in any case researchers now believe that inference is unlikely to be successful with only 80% of word tokens known, and becomes consistently practical at levels more like 95%, or one unknown word in 20. Laufer (1989, 1992) and Hirsh and Nation (1992) converge in his view, and it can be experienced directly if the reader repeats the exercise above with two words unknown in 40 (or 5%):
If current planting rates are maintained with planting targets satisfied in each _____ and the forests milled at the earliest opportunity, the available wood supplies could further increase to about 36 million _____ meters annually in the period 2001-2015.
Therefore, a suitable goal for academic second-language readers is to learn enough words to transform texts in their area of specialisation from texts of the first type into texts of the second. Then, true independent lexical acquisition would actually be possible; words would be either completely inferable from context, or else narrowed sufficiently for a dictionary to be of substantial use. However, the distance from 80% to 95% is larger than it looks.
This can be seen in the following well-replicated corpus finding (Carroll, Davies, and Richman, 1971, cited in Nation, 1990, p.17):
Different words |
Percent of average text |
| 86,741 | 100 % |
| 43,831 | 99.0 |
| 5,000 | 89.4 |
| 3,000 | 85.2 |
| 2,000 | 81.3 |
| 1,000 | 49.0 |
| 10 | 23.7 |
From this information, it appears that for learners to know even 18 words in 20 (90% of an average text), direct vocabulary instruction would have to proceed from 2000 words to 5000. The problem, of course, is that the size of this task leads straight back to the impossible time frame that lexical tutoring was supposed to avoid in the first place. Learning 3000 more words would be a task of at least three terms, even at the accelerated rate of PET·2000's best users. So direct teaching of 90% of the words of English is not a very feasible goal, and 95% is out of the question. In other words, a major portion of building a native-size lexicon must apparently be left to the winds of fate, as it has always been. However, a pessimistic conclusion could be premature.
In Chapter 1, the work of Nation and colleagues was offered as a good example of the benefits of the statistical analysis of language to course design. These researchers believed that for specific genres of text there might be high-frequency lexical islands beyond the 2000 level, which if identified could provide shortcuts to reaching the 95% mark within these genres. The genres of interest are academic discourse in general and then the discourse of specific subjects.
First, academic discourse in general. The search for a zone of academic discourse has been going on since the early 1970s, well before the era of corpus and concordance. Most of this work was undertaken in places where large numbers of students were suddenly destined for academic studies in English. One of these was the American University of Beirut, effectively the main university for the Arabian Gulf in the early days of oil. Jean Praninskas worked in Beirut in this period and found her students in desperate need of vocabulary, much like their Omani brothers and sisters more than two decades later. She found, moreover, that this need unexpectedly persisted even after the 2000 level had been attained.
In a pre-computational corpus analysis, Praninskas copied out every tenth page of ten of her students' first-year academic texts producing a corpus of 272,466 running words. She submitted this corpus to a frequency analysis with a computer program, producing a list of word families in order of frequency. Then she subtracted out West's (1953) 2000 list, and was left with a high-frequency residue of 507 headwords occurring across all ten texts. Interestingly, most of these words were Latin based. Arabic, of course, provides no easy cognate route into this lexical zone, while most European languages do (as shown by Ard and Homburg, 1983). So Arabs and others with non-Indo-European first languages have special needs in this lexical range. Praninskas' 507 words were published as the American University Word List (1972) and became the focus of a successful introductory vocabulary course in Beirut (which was probably followed by many present-day Gulf state ministers and business leaders).
Xue and Nation's (1984) contribution was to gather together four academic vocabulary lists developed in the 1970s by methods similar to Praninskas' and combine them to produce an integrated list of just over 800 words which they called the University Word List (UWL). This list has been widely used in developing countries in the last decade, particularly in countries where the first language is unrelated to Latin. Ironically, it is not used in any Gulf university that I know of at present.
When eventually tested against computer corpora, the UWL has shown itself to be in some need of revision (Hayden, 1995), but in the main its existence has been confirmed and its importance even better specified. Sutarsyah, Nation and Kennedy (1994) assembled a computer corpus of more than 300,000 words from 160 subject areas and found that, as expected, 2000 word families accounted for roughly 80% of the individual words across this corpus, as they would across any, and that the UWL accounted for an additional 10% of the individual words in this particular corpus. Thus a student who knew the 2000 list plus the UWL would know 90% of the words in his or her academic texts. Learning 850 words may seem a lot of work merely to move from 80% to 90%, but seen in terms of the progress toward independent learning, it cuts the proportion of unknowns to knowns in half--from 2 unknown in 10, to 1 in 10.
So the logical extension of PET·2000 is to expand it to include the UWL and of course a second corpus to exemplify it. Extensibility, as discussed in Chapters 5 and 10, is among the desiderata for a lexical tutor and one of the strengths of the concordance approach.
An extended version of PET·2000 was developed in January 1996 and trialed with 46 Band 4 students in the College of Commerce at SQU, February-May 1996, as shown in Figure 13.1.
The UWL was built in as a start-up option, and attached to it was Oxford's million-word MicroConcord Corpus "A" (five genres of writing from The Independent newspaper). The UWL was broken into weekly chunks of about 70 words each, and a further set of weekly quizzes was prepared. The computer interface and procedures were all exactly the same as before, and the users of the extended tutor were mainly veterans. The only difference was the difficulty of the words and especially the corpus. The Latin orientation of the wordlist is clear in Figure 13.1 above and Figure 13.2 below.
The 12 weekly quizzes follow the usual format.
As before, the lexis of the texts other than the to-be-placed words themselves is constrained, here to the 2000 list plus the UWL list as covered to date, with the aid of the EspritDeCorpus software. Unfortunately, a similar degree of lexical control on the corpus itself was impractical to exercise. The MicroConcord corpus was not passed through the EspritDeCorpus filter, since for a million words this would be a labour of many months even computer-aided. In other words, it was possible that this corpus would be too difficult for some of the students.
The students felt that they benefited from exposure to the UWL words, as might be predicted from Praninskas' work with Arabic speakers and academic English. A survey of students' attitudes to learning the UWL (Appendix H) shows that 61% thought learning these words was "very useful," and 61% thought 70 academic words a week was "difficult" while only 4% thought it was "impossible."
As for learning the words from the corpus tutor, the finding is less positive. Language instructors reported that the students found the MicroConcord corpus too difficult to use as a word-learning tool, and in their survey the students made it clear this was true. The ratio of unknown to known words was apparently too high to facilitate inferential learning, even with concordance facilitating the negotiation of input. In light of the discussion above, and well after the fact, it was indeed predictable that students with 2000 words would not have the necessary base for making useful inferences. But at time of development, the decision to use this corpus for this purpose was an honest mistake. So most students adopted a dictionary-based learning strategy, by-passing the corpus.
This turn of events was a setback, as often occurs in computer work in real-life settings. Nonetheless it opened up some opportunities for learning more about corpus tutoring. The same measures used in the PET·200 and PET·2000 studies were applied to the UWL students, the Levels Test pre-post (but at the UWL level) and the weekly quizzes divided for definition and text tasks. These measures should enable the testing of some predictions about word learning related to non-use of the corpus: First, the students will adopt a definitional learning strategy. Second, definitional gains will be small between pre and post, although not necessarily week to week, because without text work the definitional learning will not be retained. Third, on the weekly quizzes text-task scores will be lower than definition-task scores.
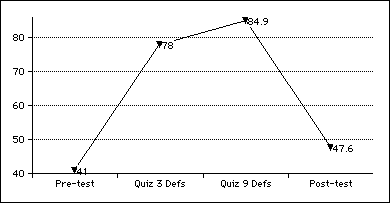
Data was collected in the spring term of 1996 for 29 Band 4 students in two intact groups. On the UWL part of the Levels Test, the subjects pre-tested at 41.0% (SD 15.3) and post-tested at 47.6% (SD 14.3). This represented a gain of 6.6%, significant (t(28)=2.68, p<.05) but small, as predicted. In terms of the 800 UWL words, it is only about 50 new words. But on the weekly quizzes, scores on the definition part of the quizzes had been high. The Quiz 3 mean was 78.0% (SD 15.1) and Quiz 9 was 84.9% (SD 12.7). So it appears the definitions were learned but not retained.
Also as predicted, the text-task scores on these quizzes were markedly lower than the definition scores. The text-task mean for Quiz 3 was 60.3% (SD 25), for Quiz 9 it was 72.2% (SD 19.6), as shown in Figure 13.4.
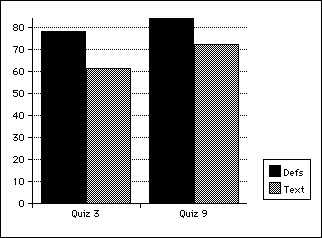
So once again, it appears that definitional knowledge of words does not show up in the text task, and further that definitional knowledge by itself is poorly retained.
It would probably not be fair to say that the students were learning nothing in this experiment. The weekly quiz trend is clearly in the right direction on both measures, and the Level Test score probably fails to pick up some learning that actually took place.
The students were well aware of what was missing from this instructional design, as they made clear in their answers to the questionnaire on their UWL work (Appendix H). Although most students could not get comprehensible examples from the corpus, 76% wanted teachers to help them learn the words by "presenting the way words are used in sentences more in class." The problem with that, of course, is that exemplifying 800 new words in class is effectively the old "rich" instruction of Beck and colleagues (1982) that the corpus tutor is trying to deliver more efficiently. The development of a usable corpus is clearly the major challenge.
The claim made above that a corpus tutor is "easily extendible" apparently needs some modification. While it is true that large supplies of text are readily available at present, the instructional value of authentic corpora at least for lexical growth appears to be far from obvious. The exact cost of developing a special corpus to carry the UWL remains to be seen, but it is still probably less than developing 800 dedicated definitions or pregnant contexts. The way to go about the task is probably not to start with a million-word corpus and begin simplifying, but to proceed in the opposite direction (as with the 2000-level corpus) from a collection of texts that the students are familiar with and build it up. The definition of this corpus is presumably that it should contain no words beyond the 2000 list plus the UWL, just as the definition of the previous corpus was that it should contain no words off the 2000 list. With a suitable corpus, there is no reason that the UWL will not be as amenable as the 2000 list to a complete self-access treatment.
There is a long way to go before the UWL extension will be running at full speed, but even so that will not be the end of the road for the tutor. Nation has suggested that direct instruction should continue until inferential learning is feasible, in other words until 19 words in 20 are known in an average text or 95% of word tokens. The difference between 90% and 95% may seem negligible, but in fact between the two figures there is another halving effect, from 1 unknown word in 10, to 1 in 20. The importance of this difference is clear when visualized as lines of printed text, an unknown word every line vs every second line.
Learning 95% of the words of English on an entirely naturalistic basis is a labour of many years; it effectively brings the learner to the lower bound of the native lexicon, about 13,000 word families by one recent calculation (Goulden, Nation, and Read, 1990). Fortunately, once again corpus analysis can identify feasible sub-sets of the task within discourse genres, in this case the discourse of specific academic subjects.
Sutarsyah, Nation and Kennedy (1994) developed a 300,000-word corpus of texts within a specific discipline, economics, and found that after the 2000 range and the UWL had been subtracted out of the corpus by their computer program VocabProfile (Hwang and Nation, 1994), about half the remaining 10% of the words consisted of a relatively small group of heavily repeated, domain-specific, technical terms. In other words, there appears to be a third high-frequency level within specific disciplines, or at least the specific discipline of economics, that could be the focus of a third and final vocabulary course that would take a learner up to 95% and lexical independence. Whether other disciplines have similar lexical cores is an empirical question, although the default assumption is that they do.
Concordance technology is capable both of finding the high frequency lexis within a discipline, and then presenting it to students tutorially. For both tasks, the challenge as always is the corpus. Typing up whole course textbooks to feed into the concordance program is not easy, even with the help of a scanner. However, as corpus applications become more widely known and used, publishing companies will probably respond to instructors' demands for on-line versions of their books. With a textbook in machine-readable form, any concordance program can easily identify its raw lexical core, and then VocabProfile or EspritDeCorpus can subtract out the 2000 list and the UWL, exposing the specific lexical core of the subject. That core then becomes a third list for instruction, and the textbook(s) becomes the corpus, possibly unmodified in this case. It goes without saying that more textbooks are better then fewer in this process; and that if the approach proves successful in one discipline, it will probably prove successful in many.
The best-case scenario for both the UWL and subject-specific extensions is that a single subject-specific corpus might be adequate to both tasks. After all, the UWL is as much present in a subject-specific corpus as in a multi-discipline corpus. The UWL and a subject-specific lexis might be able to bootstrap one another if they were taught at the same time, particularly if the subject-specific lexis was getting a lot of concurrent exposure and motivation in a subject-area classroom. There is no rigid sequence of UWL then subject lexis, as there presumably was for 2000 then UWL, and the subject lexis might as easily provide the inferential base for the UWL as vice versa.
The final goal is to have a three-part lexical tutor that accompanies learners from minimal reading ability to independent reading in an academic discipline. It is by no means proposed that such a tutor would be sufficient in itself, just an important complement to the usual classroom materials and activities. Given the unlikelihood that published coursebooks will ever guarantee either lexical coverage or enough exposures for learning to occur, this tutor would operate quietly in the background guaranteeing both.
| contents |