
The role of the computer in modern science is well known. In physics and biology, the computer's ability to store and process massive amounts of information has disclosed patterns and regularities in nature beyond the limits of normal human experience (Pagels, 1988). Similarly in language study, computer analysis of large texts reveals facts about language that are not limited to what people can experience, remember, or intuit. In the natural sciences, however, the computer merely continues the extension of the human sensorium that began two centuries ago with the telescope and microscope. But the study of language did not have its telescope or microscope; the computer is its first analytical tool, making feasible for the first time a truly empirical science of language.
The computational analysis of language began in the 1960s when large machine-readable collections of texts, or corpora, were assembled and then typed onto computer disks. An early corpus was Brown University's million-word "computational analysis of present-day American English" (Kucera and Francis, 1967), selected from 500 different sources of 2000 words each in 15 genres ranging from newspapers to scientific journals. As recently as a decade ago a large corpus was thought to be a million words, but now corpora of 100 million words and beyond have become common as capacity, text availability, and processing power expand.
A corpus once assembled is processed by a computer program whose output is a concordance, an index of all the words in the corpus along with their immediate linguistic contexts and some information about the frequency and location of each. Below are the three main windows from a modern concordance program (Antworth, 1993) using a familiar text as its mini-corpus. The first window contains the source text:
Clicking on any word in the source text produces a concordance, usually in the KWIC (keyword in context) format, in this case also giving the line number of each in the source text.

In this particular program, a further click on the concordance line has two outcomes: it traces the line back to its source text in the text window, and in a third window gives the frequency of the keyword in the corpus and a list of all the line numbers in the source text where the word occurs:

In spite of a certain superficiality in this type of analysis-it does not reveal that "cat" and "cats" are really one word, or "draw (a picture)" and "draw (your gun)" really two-concordance data nonetheless reveals language patterns invisible to either naked eye or intuition because of the huge amount of data that can be assembled.
Ironically, one of the main insights provided by assembling large amounts of linguistic data is that languages are in a sense rather small. Corpus analysis shows languages to be highly skewed statistically, with just a few items (whether words, suffixes, or syntactic patterns) accounting for most occurrences, surrounded by a large array of infrequently used options. The classic finding is that about 2500 word families (words plus their inflections and most usual derivational suffixes) reliably account for 80% of the individual words in English texts, whether corpus-size or page-size, with minor variation for genre. Kucera (1982) ties this finding to people's needs for both redundancy and novelty in language: the 2500 words provide mainly redundancy, the rest mainly new information. Rayner and Duffy's (1986) finding that in reading, low-frequency words are reliably fixated 80 milliseconds longer than high-frequency words lends psychological support to the idea.
A computer is not strictly necessary to engage in "concordancing," as the activity of making or using concordances is called. There were many concordances before there were computers, for example the concordances of the Bible that Reformation concordancers produced entirely by hand. One use of these was to give preachers a handy source of themes for their sermons. One can imagine that extracting the themes from the Bible, a large and unwieldy corpus written by many authors over centuries, would be greatly aided by a concordance. Effectively, concordancing turned the Bible into a hypertext, allowing criss-crossings and juxtapositions difficult to perceive or keep track of in a linear text of any size. A sermon on "sacrifice" could easily be built on a concordance for the word, yielding insights and relationships most churchgoers would not have thought of. Another use of Bible concordances with some modern echoes was their role in doctrinal disputes when enforced interpretations of scripture were confronted by direct examination of textual evidence.
While corpus linguistics is not quite a revolt against an authoritarian ideology, it is nonetheless an argument for greater reliance on evidence than has been common in the study of language. In classical Chomskyan linguistics (Chomsky, 1965), empirical evidence plays a relatively minor role in building up a description of language. The data to be explained by a linguistic theory, in Chomsky's view, are native speakers' intuitions about their language, not the infinite minutiae of the language itself. Language is learnable because the system is in the head, not in the ambient linguistic evidence, which consists mainly of incoherent bits and pieces-"degenerate input," in the famous phrase (as argued in Chomsky vs Skinner, 1959). However, empirical research has since established that the system is not only in the head. Language learning relies more on linguistic evidence than Chomsky allowed (Larsen-Freeman and Long, 1991, p. 238); and computer analysis of very large corpora has revealed a level of systematicity in surface language that, while possibly inaudible to the naked ear and invisible to the naked eye, is not necessarily imperceptible to the mind over time.
Non-empirical approaches to language study have produced or at least sheltered a good deal of incorrect information. This misinformation is of two kinds. In Sinclair's (1985) words, "On the one hand, there is now ample evidence of the existence of significant language patterns which have gone largely unrecorded in centuries of study; on the other hand there is a dearth of support for some phenomena which are regularly put forward as normal patterns of English." The specific intuitions contradicted by evidence are by now legion (many can be found in Leech, 1987, and Aarts, 1991). For example, intuition suggests the word "back" to be mainly a noun denoting a body region, plus some metaphorical derivatives like "come back"; but, while this interpretation may be historically true, or mnemonically useful, corpus analysis reveals "come back" to be the overwhelmingly primary meaning of the word at present. Yet in a standard English dictionary, with word senses supposedly listed by frequency, this meaning appears in 47th place (as observed by Sinclair, 1991, p. 112).
Piecemeal accumulation of this type of evidence is forcing the radical restructuring of frameworks in linguistics (discussed in Owen, 1993). For example, corpus analysis reveals that many individual words have their own private quasi-grammatical systems of collocation (accompanying words) to an extent unnoticed prior to computerized pattern extraction, to the point that the basic unit of language analysis may be more usefully characterised as lexis rather than syntax. Whatever degree of restructuring is ultimately necessary, the impact of corpus study on linguistics is likely to be large, and on applied linguistics it could be even larger.
The information provided by corpus analysis is of growing interest to language educators. Initially, when only a handful of mainframe computers in the world could hold enough text to make corpus analysis possible, educators had to take corpus linguists' word on the new shape of language that was emerging; but as the technology became more accessible, language educators could become applied corpus linguists themselves. Leech and Fligelstone (1992) discuss the natural extension of corpus analysis into education:
In the last few years, a remarkable upsurge of interest in corpus linguistics has taken place. So far corpus work has been largely restricted to those who have access to powerful hardware, capable of handling the large amount of text which it often involves. But as hardware becomes both cheaper and more powerful, this will change, and we may expect corpus resources to become more readily available for use, not only for academic and industrial research, but also for educational applications (p. 137).
Applied linguists and researchers in language instruction have recently begun adopting computational techniques, often with striking results. Biber, Conrad and Reppen (1994) discuss the philosophy, methodology, and some of the fruits of applying corpus insights to areas of language instruction like curriculum design.
For example, even after a relatively brief period of applied corpus analysis, it now seems clear that many commercial, intuition-based grammars, dictionaries, and language courses have been guilty of purveying a version of English well out of date. High and low frequency items and structures are randomly mixed for their customers' consumption, in packages ranging from mildly time wasting to plain wrong. A telling example is in the pre-corpus approach to vocabulary acquisition. As mentioned above, the lexicon of English centres on a high-frequency core of about 2000 word families; but most language courses do not emphasize these particular words, offering instead a random smattering of lexis from several frequency zones (also noted by Meara, 1980; Sinclair and Renouf, 1988)-effectively alerting learners to words they may never see again, while keeping silent about those they will surely meet often.
A good example of the benefits of applying corpus analysis to vocabulary instruction can be found in the recent work of Paul Nation and colleagues in New Zealand. Two projects give some of the flavour of what corpora can teach language course developers. First, Sutarsyah, Nation, and Kennedy (1994) used a corpus study to crack one of the oldest conundrums in second-language reading: How many general English words and how many subject-specific words does a learner need to comprehend a subject-area text? Traditionally, such a question has been considered simply unanswerable. Nation and colleagues compared two 320,000 word corpora, one from 160 different subject areas, and the other from a single academic discipline, economics. They found that a relatively small core of under 3000 general English words was common to all subject areas; and that although the economics corpus had its own private lexis, this was rather small and heavily repeated. In other words, with corpus analysis, the lexical requirement for reading in an academic area is definable.
A second example is Bauer and Nation (1993), which examines among other things the frequency of affixes in English. English morphology (adding -ize, -ation, -ic, etc to words) is one of the many problems of learning English that are traditionally viewed as insurmountable except through long years of familiarization. Some course materials offer learners a shortcut through the maze of affixes; for example the Longman learner's dictionary (Proctor, 1979) isolates the affixes in a special list and marks certain ones as "most common." When Nation and colleagues submitted the main 91 affixes of English to a frequency analysis in a million-word corpus, they found that there were actually few frequent affixes, only 29, once again showing the skewed nature of language and suggesting a definable learning task. Predictably, only a few of these were on Longman's most-common list.
There have been some attempts to use corpus analysis to right some of the wrongs of traditional language instruction. A large-scale attempt to bring corpus insights into the design of language instruction is the COBUILD project at the University of Birmingham (Sinclair, 1987a). Starting from the assembly of a 20-million-word corpus, Sinclair and colleagues went on to produce a corpus-based learner's dictionary (Sinclair, 1987b), and then a three-volume lexically oriented course based on it (Willis, 1990; Willis and Willis, 1987; 1988). This syllabus attempts to present the language as it really is, simplified yet undistorted, in line with the frequency and other information the corpus makes available. For example, it claims to offer complete coverage of the 2500 most frequent words of the lexicon in their most frequent senses and contexts. Also, it encourages learners to see themselves as mini-corpus linguists, extracting patterns, hypotheses, and rules from samples of authentic language. However, the samples are small and have been selected to make specific points, so the learner-as-linguist fiction is a limited one.
For the most part, COBUILD presents learners with the products of computer analysis rather than inviting them to join in the process. There are two reasons for this. First, until recently the technology available in schools and universities would have been underpowered to handle a corpus of any size. Second, educators have felt that computer analysis might be a source of overload and confusion for learners rather than enlightenment. However, the idea of hands-on concordance activities for learners seems a natural extension of trends in linguistics, and has occurred to many CALL (computer assisted language learning) developers on the look-out for new ideas. Also, student concordancing seems a clear application of constructivist ideas about learning (Brown, Collins, and Duguid, 1989; Bednar, Cunningham, Duffy, and Perry, 1991), whereby learners are characterized as "scientists," in this case linguists or lexicographers, using modified scientific research tools to handle raw rather than pre-encoded data. Further, the analogy between searching a corpus with a concordance and browsing the Internet with a search engine provides some topical cachet.
Of course, any similarity between the linguist's and the language learner's computing needs is superficial, unless there is some reason to think that both require the same types of information about language. It is possible to argue that they do. Learners need to make some of the same distinctions that linguists do. For example, if linguists need to distinguish core from periphery in a language, then learners need to even more since they do not have the time to learn an unedited version of the language as children do. For example, if a learner was anxious about the difference between "will" and "shall" and ran a concordance on these words from the MicroConcord Corpus A (Oxford, 1993), he or she would see that "will" outnumbers "shall" 1224 to 9, in other words that the distinction is disappearing from the language and not worth learning. Using a concordance, a student can learn in two minutes what a native speaker knows from decades of experience. Of course, this information could be provided in a coursebook without learners having to use concordance programs themselves, but it is unlikely that any coursebook writer could predict all the questions about language that a learner might have.
Learners also need to make some of the same pattern perceptions that linguists do. Linguists use the computer to expose the patterns hidden in a large distributed data source, learning for example that the current main sense of the word "own" is "my own house" rather than "own a house," a piece of information which, without a computer, is distributed throughout the universe of discourse to the point of invisibility. Similarly, in lexical acquisition research it is well known that a word's meaning is partial in any given instance of its use, so that meeting a word several times in several contexts is necessary for assembling and integrating a complete representation of its meaning. Using a concordance, a learner can bring together contexts otherwise spread over months and years of natural distribution and consider them all at once.
Willis (1990), co-author of the COBUILD course, sees hands-on learner concordancing as the next logical step in the COBUILD process:
In the Collins COBUILD English Course we, as materials writers, acted as intermediaries between learners and corpus, taking decisions as to what was worth highlighting and when. It is now technically possible to bring decisions of this kind much closer to the classroom.
Students themselves can have access to a corpus. Using the FIND command on a word processing package they can examine a range of uses of a given word in its original contexts. Using a concordancing programme they can bring those uses together and either compare them with a description provided by a teacher or a set of materials, or produce their own description. Given the rapidly improving state of technology it is more than likely that the notion of the learner's corpus will play a progressively larger part in the repertoire of the coursewriter, the teacher and the learner. In future we may come to think of the business of designing a syllabus as a process of constructing and exploiting a corpus of language with a particular group of learners in mind (p. 131-2).
Indeed, the idea of a learner's corpus and concordance has seemed an almost obvious vein for developers and theorists in CALL to work on. In the recent literature, corpus and concordance are regularly described as the most promising current idea (for example Leech and Candlin, 1986; Clarke, 1992; Hanson-Smith, 1993). Concordancing is the centrefold idea in a paradigm-shift within CALL from computer as "magister" to computer as "pedagogue" (Higgins, 1988), from a tutor-dominated, process-control model of language instruction, to an "information resource" model, where the learner is free to explore the language for himself, leaving the instructor in the role of providing tools and resources for doing so.
No one has done more than Tim Johns at Birmingham to promote concordancing, or what he calls "data-driven learning," through a series of discussion papers (1986, 1988, 1991a) and the development of several corpora and concordancers culminating in the Oxford MicroConcord package (1993). This package consists of a learner's concordancer, a million-word corpus of British newspaper text, another of academic text, and an accompanying manual expanding on the practice and principles of concordancing (Scott and Johns, 1993).
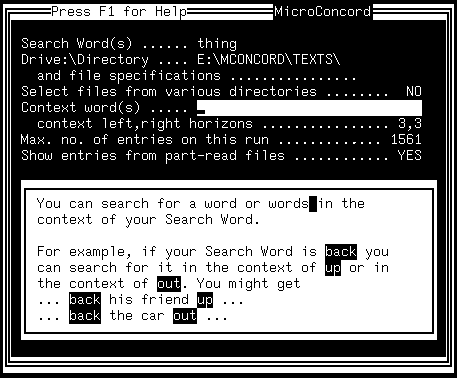
As its opening screen (Figure 2.4) shows, MicroConcord allows learners several options for satisfying whatever curiosity they may have about English. A word such as "book" is entered for search, which will produce a listing of all occurrences in the corpus containing this string. Or learners can constrain the search to the precise forms of the word, or the collocates, prefixes, or suffixes they are interested in.

A possible limitation on MicroConcord, however, is that its interface assumes a learner with a good deal of curiosity about language, in addition to a fairly high reading ability and knowledge of computing, as for example would be needed to make sense of the program's collocational search options (Figure 2.5). Nevertheless, it seems that advanced students can be guided to get some benefit and enjoyment from software like MicroConcord, as suggested by several descriptive reports in Johns and King (1991).
But do students actually learn anything from having a massive body of text assembled for them and chopped up by a concordance routine, that they couldn't learn better and easier through the usual media and technologies? There have been some problems answering this question, or even finding a way to ask it.
Student concordancing has generated a lot of enthusiasm but little empirical research. Of the several studies of student concordancing gathered into Johns and King (1991), only one presented any quantitative data about the learning effectiveness of concordances, and that was an off-line study. Vance Stevens (1991) at Sultan Qaboos University in Oman predicted that learners would be able to retrieve a word from memory more successfully when cued by several pre-selected concordance lines with the key word masked than by a single gapped sentence. His prediction was confirmed, so this was at least an existence proof for a facilitating effect of concordance data on some aspect of language processing, and a hint of a possible role in learning.
But other than Stevens' study, none of the other pieces ventured beyond describing students in various concordance activities in guided lab sessions. No theoretical underpinnings were explored, no falsifiable hypotheses formulated, no learning outcomes measured. None of the studies suggested that learners underwent more than one or two lab sessions, or asked whether learners ever consulted a corpus again. Nor did this situation appear to be atypical: asked whether he knew of any empirical study of any aspect of student concordancing, other than Stevens' study, Johns (personal communication, 1994) replied that he did not. And, although he had "often proposed the idea to [his] graduate students", none had ever taken it up. An ERIC search in February 1996 with "concordance" as the search word confirms the trend: there is lots of interest from teachers who happen to be CALL enthusiasts, but no hard studies of student users.
Some reasons for the lack of hard studies could be ventured. First, it is doubtful that students have ever used concordancing enough to generate a very large database so that even initial pattern-perception can begin. Second, if they did, none of the commercial concordance programs can generate user protocols, so research is limited to observation and anecdote. Third, even with protocols, in an open-exploration environment there is no learning task built in and no way of knowing for certain what learners are trying to learn or whether they are succeeding. Fourth, the way concordancing is typically introduced to students does not allow variables to be isolated in any straightforward research design. The introductions to concordancing described in the literature invariably confront learners with three rather novel experiences at the same time: concordance data as a representational format (large numbers of chopped-off lines, source texts that fill entire screens); authentic texts, usually at a level higher than they have seen before; and a series of complex human-machine interactions (as suggested by Figure 2.4 and 2.5 above).
So an empirical study of student concordancing would have to find a way to build up some volume of use, develop a tracking system, attach or build in a specific learning task, and find a way to introduce one novelty at a time.
This lack of hard research is not merely a missing step in an academic ritual, but a real problem leading to an under-implementation of a potentially powerful idea. Without the benefit of an instructional design process guided by research, the concordancing idea is now widely seen as running into trouble.
According to several recent studies and reviews, the open-exploration model of concordancing has apparently over-estimated the needs of learners to get their hands on raw linguistic data-or at least over-estimated the amount of this data they can cope with. For example, in a review of the various types of CALL available for vocabulary instruction, Goodfellow (1995a, p. 223) argues that the information-resource paradigm has now begun to show itself just as "deficient for learning purposes" as the tutor paradigm seemed a decade ago. His solution, however, is not to return to the tutor paradigm, but to look for some middle way, in the direction of research-supported "tutorial support for the use of lexical resources." The idea of supported exploration, and particularly of support built into modified scientific instruments, picks up a theme from the literature of constructivism in educational technology (for example Bednar and colleagues, 1991).
However, the middle way in concordancing has proven difficult to find, and any modification of the open-exploration model has tended to lead straight back to the bad old magister/tutor. A recent approach to using corpora with language learners (Tribble and Jones, 1990; Johns, 1991b) has involved presenting them with pre-selected off-line concordance data (i.e. sheets of paper). For example, learners use a concordance printout centering on several instances of the word "own" to help them answer some questions, like "Which is more common in English, own as in 'own a house,' or own as in 'my own house'?" The rationale for presenting computer data on paper is clear; it is to limit information overload by constraining the encounter with raw, voluminous data, and at the same time to eliminate the need to operate the computer interface. The only problem is, the question is the teacher's not the learner's.
Of course, pre-selected concordance data can also be presented on-line with simplified interfaces. Johns (1994) has attempted to increase his students' interest in hands-on concordancing by building a tutor, CONTEXTS, on top of his concordance program (itself on top of a corpus). The tutor poses questions for learners to answer by taking a plunge into the data beneath. However, in this case the data has been warmed up a little; according to Goodfellow, CONTEXTS presents learners with "fixed numbers of pre-selected citations" to make specific points about grammar or lexis. In other words, student concordancers, once modeled as explorers of linguistic data for its own sake (Johns, 1986), are now pupils being shown selected examples of language points that they would never notice for themselves (Johns, 1994).
Whether on-line or off-line, there are two problems with pre-selected concordance data. Theoretically, any learning advantage that might accrue to a genuine process of "discovery" or "construction," in other words to making sense of raw data, is compromised if the data has already been made sense of by somebody else. By selecting what data learners should look at, and why they should look at it, the instructional designer pre-encodes the data for them to an unknown degree. Practically, the labour of pre-selecting concordance lines to illustrate specific points is very time consuming, and effectively means that learners will be exposed to a limited number of concordancing experiences. This is a pity, because one of the potential advantages of learning from corpora is that there is no limit to the information that an inquiring learner can find there. Surely, it is not beyond the wit of man to bring learner and corpus together in a way that neither compromises the essential idea of concordancing nor pre-limits the amount of program use.
Goodfellow proposes that the middle way between tutor and information-resource paradigms in CALL will be found only as the result of a "serious research effort." This presumably means experimenting with several types of concordance interfaces, with varying degrees of tutorial support, which can then be tested and compared for their ability to promote use and learning. This seems indisputable; wobbling without principle between open exploration and over-guidance can only send concordancing the way of language labs, television learning and other great technologies that never lived up to their promise. The present study proposes to take a guess at where this middle lies, build a tutor there, get learners to use it, and find out if any learning takes place that can be attributed to the concordance medium per se. The meaning of "middle" here is a concordance tutor offering the maximum tutorial support that does not compromise the essential idea of concordancing.
Before proceeding, it will be useful to expand on this "essence of concordancing" that should not be compromised if the learner is to be described as in some sense "doing research." How much support is too much? The minimum idea of concordancing proposed in this study is that the power of the computer should be used to generate novel, unpredictable information, as opposed to driving a presentational device for pre-encoded information. If this minimum is not present in an instructional activity going by the name of concordancing, then it is doubtful that the activity is making any serious use of computer power or that the learner can be described as doing research.
But as mentioned above, the learning power of concordancing can only be tested if we know what the learner is trying to learn, and so a task should be built into the tutor that can generate testable hypotheses about what if any success he or she is having. There are many things one can imagine learning from a large corpus of language, but in this study the learning task will be learning the meanings of words from meeting them in several contexts. The draft hypothesis, to be refined in the next chapter, is that concordancing can simulate important aspects of vocabulary acquisition from natural reading but in a reduced time frame.
For the study to proceed, the following are now needed: some reasons for thinking that corpus and concordance might be a useful tool for learning words (Chapter 3, 4, 5); some subjects with a specific need and motivation to learn some words (Chapter 6); and a corpus and concordance interface that can facilitate lexical acquisition for these students, track their learning strategies, and isolate the concordance format as an independent variable (Chapters 8 and 10).
| contents |