
Several findings from the study of PET·200 augur well for the development of a larger scale lexical tutor. Students used the tutor a lot, in their own time; they tended to use it fully, not just as a source of cheap definitions; the quality of learning was at least equal to that of the classroom; and the pace of lexical growth was faster than is normally expected. Most interesting, it appears that the concordance information was useful. From this base-camp, an attack on the complete 2400 words and beyond can be mounted.
And yet expanding PET·200 into PET·2000 is not straightforward. In the review of lexical tutors in Chapter 5, there is often a problem getting beyond the 1000-word mark, as massive amounts of hand-coding loom up whether in a pregnant contexts or definitions approach. But a further problem for lexical tutors at about this point is the exponential growth of variance in the learning task. In PET·200, it could be assumed that learners (with about 500 words) needed all the words on offer; but now, with about 1000 words in their heads and at least 500 more needed to reach Band 4 range, there will be enormous variation in the 2000-level words known, semi-known, and unknown, even for students who have completed an identical program of instruction.
This variance in vocabulary knowledge was originally documented by Saragi, Nation, and Meister (1978), and confirms the incremental nature of the learning process. The finding was replicated with SQU students graduating from Band 2/PET·200. The method was simply to check variance in students' knowledge of the 18 items used at the 2000 level of the Levels Test. The subjects are the same 11 students whose efforts were followed in the previous chapter, whose Levels Test scores had just risen to more than 1000 words, roughly 9 out of 18 items. Figure 10.1 shows the extent of the variance.
On average, each student knows 9.8 words out of 18, and each word is known to 6.2 students. In other words, each student knows about half the words, and each word is known to about half the students. By extrapolation, a common core of about a quarter (1/2 x 1/2) of the 2000, or only 500 words, is shared by students who know 1000 words. So as the number of words known increases, the proportion of overlap shrinks, at least in early stages of lexical development.
Of course, the variance in words known is only a fraction of an even greater variance-words yet to learn. Of the 2000 words, 1500 are outside the core of words known, despite the fact that each student knows 1000! In other words, it is no longer possible to say with any confidence which words a learner needs to learn, and select, say, 500 target items for direct instruction. This variance problem appears to be quite universal, and could be a reason that the coursebooks examined in Chapter 6, and the hand-coded lexical tutors examined in Chapter 5, suddenly give up on systematic treatment of new vocabulary shortly after 1000 words. However, the learning need does not end at 1000 words, and there is no real reason for a computer tutor to end there either.
One computer solution to the variance problem would be to put the entire 2400 PET list in students' hands, attach it to a sizable corpus at a suitable level, and let students decide for themselves which words they know and don't know. This in fact is what is proposed for PET·2000, and a question to be answered in a later chapter is whether students at this level have enough awareness of what they know and don't know (lexical metacognition) to justify this way of proceeding.
The instructional design task is to integrate the 2400-word list, a matching corpus, and some text-reconstruction activities within a computer tutorial that students can understand and use. The research design task is to isolate the concordance format as an independent variable to the extent possible, in line with the goal of confirming a definable effect for the experimental treatment. Many of the exploratory studies of concordancing described earlier as inconclusive failed to disentangle the experimental treatment from other variables inherent in the technology. Often three novelties enter into subjects' lives all at the same time-the concordance format, massive authentic texts, and complex entry and interaction modes-with the effects of the separate variables not easily discerned. Fortunately, to some extent the instructional and research design tasks coincide: a level-controlled corpus and a mouse-driven entry will probably make the tutor easy for the students to understand and use, and in addition allow for isolation of the concordance format as experimental treatment.
For either design task, the sheer size of both wordlist and corpus presents some challenges. First, with an offering of 2400 PET words, any hand-coding becomes not just laborious but effectively impossible. Devising a corpus that would contain, say, three hand-coded pregnant contexts for each of 2400 words, would be a labour of many months. The procedure for generating short, corpus-based definitions for PET·200 would no longer work with the larger numbers either. The beginners' corpus was small enough to be examined for all instances of a word, and then a short definition could be devised to encompass all of them. But now, any corpus large enough to provide even a few examples for each of 2400 words will also be large enough to contain more senses of some of them than can be encompassed by any definition that 1000-level students would have the patience or skill to read.
Second, an access problem emerges as wordlist and corpus grow. To be useful to these students, the tutor must be able to develop many concordances over the course of a half-hour session, which means fast, easy access. Many concordance interfaces such as MicroConcord deliver their information rather slowly on school-sized machines. One reason is their massive corpora, such as MicroConcord's two bundled corpora which are a million words apiece. Speed of access depends on how the corpus is handled by the concordance routine (discussed below), and on how big it is. It is normally thought that only massive, slowly delivered corpora are adequate to guarantee several exemplifications for each word, but the approach here will be to develop a smaller, faster corpus with the aid of text analysis programs.
The corpus developed for PET·200 would be too small for an assault on the remainder of the 2400-word list. With PET·200, because of the limit on the number of words to be taught, almost any 20 texts at the right level would have yielded a suitable list of 240 words unlikely to be known to the students, each with a few exemplifications. But 2400 words will need a far greater number of texts to ensure a few examples of each word. The corpus initially proposed for PET·2000 was simply all the main texts the students' courses currently exposed them to, about 200 pages. These texts would be thematically familiar to the students, and the lexis presumably controlled.
But is the lexis controlled? Although we have seen that many language materials give up on systematic vocabulary shortly after 1000 words, this does not mean they do not contain vocabulary beyond that level. If they contain large numbers of low-frequency words, this will stand in the way of comprehension and learning new words from contextual inference. Here is a passage from Headway Intermediate (Soars and Soars, 1991), used as PET preparation for commerce students size-tested at just over 1000 words. The words in bold typeface are words identified by a text analysis program as being outside the PET 2400 list (i.e. words that would be opaque to a reader who already knew the 2400 words):
The Observer newspaper recently showed how easy it is, given a suitable story and a smattering of jargon, to obtain information by bluff from police computers. Computer freaks, whose hobby is breaking into official systems, don't even need to use the phone. They can connect their computers directly with any database in the country. Computers do not alter the fundamental issues. But they do multiply the risks. They allow more data to be collected on more aspects of our lives, and increase both its rapid retrievability and the likelihood of its unauthorized transfer from one agency which might have a legitimate interest in it, to another which does not. Modern computer capabilities also raise the issue of what is known in the jargon as 'total data linkage' the ability, by pressing a few buttons and waiting as little as a minute, to collate all the information about us held on all the major government and business computers into an instant dossier on any aspect of our lives (p. 74).
Out of 167 words, 30 are beyond the basic 2400, let alone beyond the basic 1000 words. This is a density of 1 difficult word in 5, absurdly out of touch with Laufer's (1992) finding that 1 in 20 is where contextual inference becomes feasible. Such absurdities in fact abound in commercial textbooks. This type of text is unlikely to teach very many words to our subjects, so no straightforward adoption of scanned course texts was possible.
Admittedly, few texts will be found that present new words in the ideal ratio of 1 unknown in 20. Even the best-designed texts in the world will still leave learners with 1000 words in the paradox of trying to learn many words from contexts that themselves contain words that are unknown or semi-known. Yet, this paradox is one that every child somehow breaks out of over the decade of first-language acquisition.
A couple of things can be done to resolve the paradox in a more restricted time-frame for second-language learners. First, as discussed above, a concordance allows learners to negotiate input, by searching through several contexts and finding one that makes sense to them (has a high proportion of the 1000 words they happen to know). Second, texts from the students' course can be constrained without too enormous a labour to the 2400 PET words themselves. Then, as expansion takes place beyond the 1000 level, the words that have been learned will feed into the contexts for learning yet others, initiating positive feedback.
These two measures might provide an escape-hatch. Whether they do is a question to be answered in a later chapter.
What is needed, then, is a corpus built from the students' course texts, but with its lexis restricted to the PET wordlist. One would think that the computer could help in this, and indeed a program called EspritDeCorpus (Cobb, 1994b) has been developed to do so. Once the entire corpus of course books was recoded in electronic form, EspritDeCorpus checked every word against the PET list, tagging any that were off-list. Of course, such word-matching programs are simple to write, but notoriously inaccurate when dealing with word families ("look" is in the list, but the program tags "looking," and so on). The usual solution, and the one adopted here, is to automate the tagging process as much as possible but leave a space for a human flagman at the choice points.
EspritDeCorpus brings in a candidate text from a hard disk or network:

Then a wordlist is loaded into memory, in this case the PET 2400 list, and the text is checked against the list:

Here EspritDeCorpus has found two words from 128 that are off-list, 1.5% of tokens in the text, so the text looks suitable as a source of contextual learning for the subjects.
However, the program makes some mistakes. In the illustration above, "don't" and "do?" are erroneously tagged as off-list merely because of some bits of punctuation attached to them, and are easily dismissed. But the program could make some more serious errors that would cause part of a text to be rejected needlessly. The program might tag "running" as off-list, although "run" was on-list; but since "+ing" is a morphological change these students could be expected to know (Bauer and Nation, 1993), then it is not necessary to reject "running." Some simple morphologies are built into EspritDeCorpus (it counts any listed word "+s" as a listed word), but for complex cases it is cheaper to bring in a human than to precode every acceptable variant.
Man and machine decide on tough cases interactively. If there is some doubt about whether a word or some form of it is a PET word, then the operator clicks on it with the mouse, and in another window the string is trimmed back through end-character deletion until either a stem is found that appears in the PET list (and it gets a ""), or else the word disappears:

"Do" is clearly on the PET list, so "don't" can be assumed to be also, although literally it is not. In cases of ambiguity, clicking on a string in the checklist itself allows the operator to make a match with the relevant segment of the PET list. The "do" example is banal, but in the case of a word like "worried," this method allows an operator to find out quickly whether or not "worry" is a PET word (Figure 10.5).
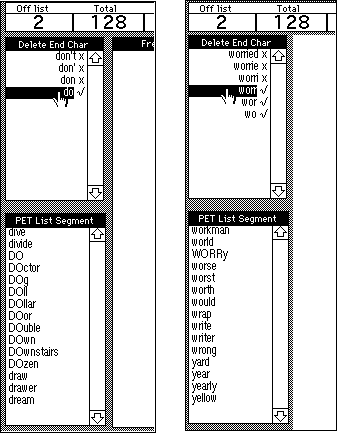
With the operator satisfied that an underlined word is merely a variant of an on-list word, he can click on the word again, removing the underlining and updating the percent-off-list figure.
By this method, a sizable text can be checked in less than a minute. The goal is to reduce the percentage of off-list words to one or two. If there is a particular paragraph that contains a large number of infrequent words, the operator may decide to delete the section (since these texts will not be read continuously anyway). Or, he can decide whether the text can survive with a few words deleted, perhaps with a small amount of re-writing. This method of corpus control has proven very efficient, and a corpus of about a megabyte can be checked and adapted in about a day.
Getting the wrong words out of the corpus is one challenge, getting the right ones in is another, and in enough times is yet another. As discussed above, each PET word should be met in at least three or four contexts. Of course more would be better.
In fact, is three or four enough? In a study of English speakers learning the "nadsat" vocabulary of the novel A Clockwork Orange (Burgess, 1962), Saragi, Nation and Meister (1978) measured word learning against number of occurrences of each word in the text, finding about 16 occurrences needed for high quality learning and a cut-off at 5, below which little learning took place. However, these subjects did not know they would be tested on the words, so their learning was entirely incidental, as would not be the case with users of a lexical tutor. Also, they were meeting the words spaced throughout several hours or days of reading, not in several contexts together. So it is not certain that two or three occurrences are not useful when time-collapsed in an intentional learning activity. The corpus built for this experiment is clearly in the nature of a trial.
Given that many commercial coursebooks abandon systematic vocabulary instruction after 1000 words, yet at the same time contain large numbers of low-frequency words, it is perhaps not surprising that in one final area they are also deficient. Even a year's worth of readings does not necessarily yield even one example, let alone three, for many of the 2400 most frequent words. So these words must be found and worked into the corpus. Once again, however, the computer's matching power can reduce the task-size. The program required for this task is EspritDeCorpus running backwards, which checks the corpus for missing PET words.
The illustration below shows PET·2000's lexical database, with EspritDeCorpus finding "C" words missing from the corpus:

The solution to a missing word is usually to hand-code a few items into the corpus, and once again the computer can help. For example, if PET-word "cocoa" is missing, it is a simple matter for EspritDeCorpus to run a search of the corpus for "drink" or "tea" and find a place where the missing beverage would fit without sounding contrived. For example, "We went home after a cold day and warmed up drinking tea..." can easily bear the addition of "and cocoa."
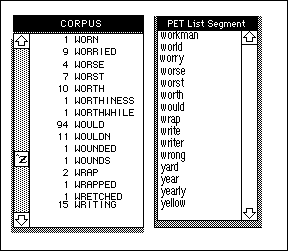
Once again, there is the problem knowing whether a word is missing or merely present in another morphology (say, "worry" is absent but "worries" is present). A way of checking for this information is simply to run a concordance on the corpus, matching its frequency list against the relevant segment of the PET list. Below, for example, it becomes clear that although the corpus does not actually contain PET-word "worry," the word actually appears nine times as "worried."
With these technical aids, it becomes manageable to build a relatively small corpus with 99% of tokens within the 2400 range and each PET word exemplified at least three times. It is a task of a working week, compared to the enormous labour to grow LEXIQUIZ from 500 to 2000 words (an additional 1500 short definitions and matching example sentences required), or Coady's tutor from 1000 to 2000 words (an additional 1000 dedicated definitions required) or Beheydt's tutor from 1000 to 2000 (an additional 4000 dedicated pregnant contexts required).
Sophisticated concordancers like MicroConcord allow numerous coding options; one can find all the instances of "come" that have "back" in the environment, and so on. While this is undoubtedly useful for a linguist, course designer, or certain type of learner, it is expensive in access speed. The flexibility is purchased by generating concordance listings from scratch, which takes a relatively long time. The idea of PET·2000, however, is to allow students to search through a corpus rapidly, for example checking briefly to see whether a particular word is already known, not necessarily pondering each and every concordance listing. For this, high-speed processing is necessary, and speed can be increased greatly if the program does not have to generate its concordances from scratch. A fixed-line concordancer pre-codes all its concordances for a specific corpus in advance and then displays them rapidly on command.
Such a high-speed concordancer is Texas (Zimmerman, 1988), which can generate a concordance for a high frequency item like "the" in less than a second, as compared to MicroConcord's ten seconds for the same item and the same corpus. TEXAS has been adapted as the program infrastructure of PET·2000, and its main user interface appears in Figure 10.8. Top left is the frequency list for the entire corpus, to the right are concordance lines generated by clicking words in the frequency list, and below are source texts generated by clicking concordance lines. TEXAS solves the access-speed problem, and is entirely mouse-driven for ease of use.

Texas also has a number of convenient features for assembling texts into corpora and adding new texts to existing corpora. The pre-coding of concordance lines for a text of two megabytes takes under a minute. Zimmerman (1992) describes some of the progamming advantages of TEXAS that make it particularly suitable for exploring a variety of concordancing configurations and corpora. He highlights the advantages of TEXAS by indicating the disadvantages of other concordancers:
All conventional database systems (that I know of) fall short in one or more ways:
In other words, TEXAS is more flexible and easier to use for both developer and end-user. Ease of getting data into the system is particularly important for exploring the learning properties of the medium and of different kinds of corpora.
While hugely easier to use and understand than MicroConcord, for tutorial purposes there are still several problems with the TEXAS interface. TEXAS presents the full frequency list for the corpus, but this would not be useful to give to students. It is easily seen that more words are represented in the frequency list than are actually on the PET list-since it includes the 1 to 2% of off-list words tolerated in corpus building ("abuse," "absorbing," and "access" in Figure 10.8). Over even a medium-size corpus, these stray words end up as quite a large number of single items, normally buried in the corpus but here given equal billing with PET words like "absent," "above," and "abroad." What the students need is the relevant sub-set of this list, not the whole thing. Also, the TEXAS corpus lines are probably numerous enough to confuse students, yet too short to tell them whether the word is familiar or not.
The biggest problem is that the source text is unfriendly, starting not merely in media res but also verging midway into a different text. In fact, it is not much friendlier than a MicroConcord source text (Figure 10.9). Learners' needs for "white space" in screen designs may not be as great as was once thought (Morrison, Ross, & O'Dell, 1991), but TEXAS and MicroConcord source texts can both be predicted to overload most language learners. The problem is not so much the number of words on display as the lack of differentiation of different categories of words and kinds of attention asked for.

The PET·2000 interface (Figure 10.10) displays all the same information as TEXAS and most of the information of MicroConcord, but in a form calculated to be more congenial to the learner. The wordlist here is not simply all the words in the corpus, just those on the PET list. The corpus lines are fewer but wider (about 40% more than is visible here). The source text is a cohesive piece of text, beginning with a capital letter and ending with a full stop, with the target word and immediate context clearly identified. The overall amount of text on the screen is de-emphasized through the use of three colours and three fonts corresponding to three types of information. It is never necessary to "go" to another screen. This interface is the first draft of a corpus tutor for lower intermediate students.

But technology and interface are less than half the job in any CALL
project;
it is in implementation that projects succeed or fail, and strategies for
implementation are discussed in the next chapter.
| contents |