
As in the discussion of PET·200, going through a run is the best way to pick up the design features of PET·2000 relevant to its implementation. On start-up, the learner enters her name and behind the scenes the program launches a protocol file:
Then Laila is asked which corpus the program should access:
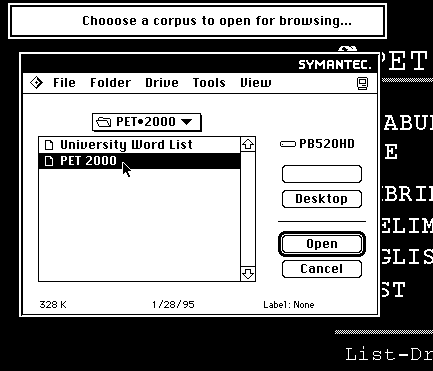
The choices are a 328-K corpus specially dedicated to the PET word list and a 1.5 MB corpus dedicated to another academic wordlist (for graduates of PET·2000). Other corpora could be offered at this point (1000-word corpus, medical corpus, business corpus, and so on).
With a corpus chosen, the main interface appears, and Laila chooses an alphabetical range of the list:

Clicking on any letter brings in the relevant list segment in a scrolling field, with the number of words in that letter indicated in the middle (129 words for "A"):
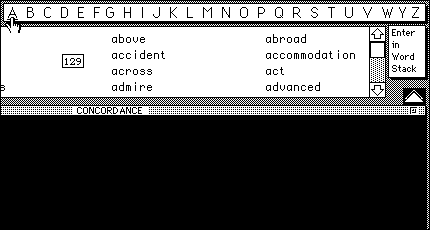
Clicking on any word underlines it, so the learner can keep track of what she has done, and then returns a concordance for the word:

The concordances produced by TEXAS are not real-time generated, but windows on a pre-coded concordance for the entire corpus. The fixed-line architecture is fast, but means that students cannot request sophisticated searches. MicroConcord for example offers "wildcards," so that entering "accept*" will pull in "accepted," "acceptable," and so on. However, TEXAS often delivers such related-word information unsolicited, as in Figure 11.5. By contrast, if a MicroConcord user does not specifically ask for related-word information, the program returns a concordance for the exact string requested only. Students at this level are unlikely to request related-word information, but they might make some connections if it is put in front of them.
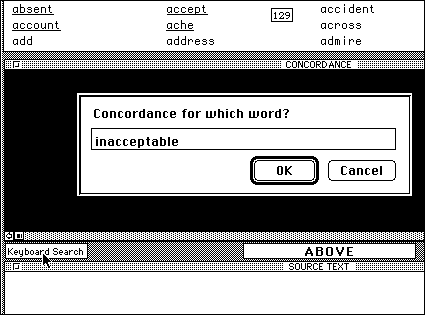
The learner is not limited to concordances generated by the PET wordlist. There are two other options. One is keyboard entry for any word learners may be curious about, say about whether "inacceptable" or "unacceptable" was the way to negate "acceptable":
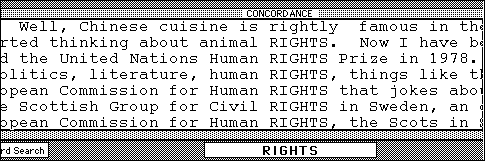
Second, from within the black concordance window, any context word can itself be clicked to produce its own concordance, giving the concordancer a hypertext dimension. Students can browse through the corpus, random-associating their way through a cyber-lexicon of whatever words catch their interest. Looking at "about," Laila spots a curious use of "right" in the vicinity:

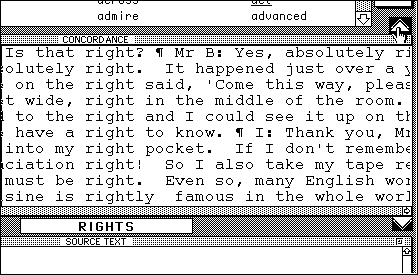
Clicking on "rights" in the concordance window returns Figure 11.8:
Then, if the student is curious about how "human rights" relates to the various senses of "right" she already knows, the arrow-up button (top right) leads to 86 instances of the word in this particular corpus, divided into strips of ten:
For a really curious learner, the final step in browsing is to power up to the University Word List (a two-click operation) and check "rights" in its dedicated corpus, the 1.5 megabytes of Independent newspaper articles bundled with MicroConcord:

Here are some of the 57 instances of "rights" offered in that corpus. The concordance window can be expanded up to 20 lines using the standard Macintosh "grow" button.
While few students may stretch the system this far, the design principle is that there should be more things to think about and do than any student will ever get around to, so that the tutor is never the limiting factor in learning. In fact, only a handful of the hundreds of students who have used PET·2000 have ever jumped back and forth between concordances and corpora, but the point is that some have.
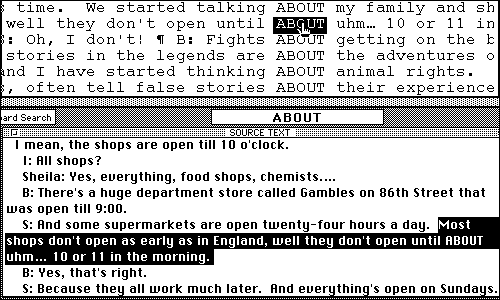
The system has to cater to all types of users, mainly ones needing more guidance than the aggressive browser dramatized above. For most users, the sequence is to search through the PET words, thinking about which ones they know, sort of know, and do not know. Choices and metacognition are forced by the large number of words to be learned every week. For example the Week 1 assignment is 287 A+B words, more than the students can handle without prioritizing. When they find a word they want to know more about, they search through concordance lines (meeting words multicontextually) until they find an example that makes sense (negotiating comprehensible input). When a reasonable candidate has been found, they can click for an expanded context for the word. This is presented in a format designed to be as clear and legible as possible. Here a learner expands the context for "about":

Students often search for at least two examples that are clear to them. Here a learner has noticed a second sense of "about" and is considering a second source-text:
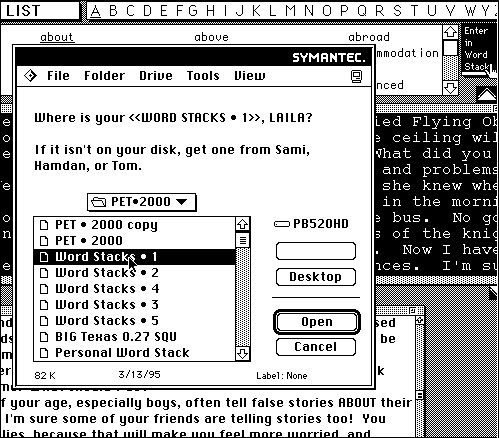
A complaint about concordancing often made by teachers is that once some information has been produced on the computer screen, there is nothing further for students to "do" with it. In PET·2000, the search for clear examples is just the first of several possible steps. Not all users go through all the steps, but few skip the first one, which is to send the words they have found to a database where they can be printed up as a personalized glossary. Here Laila has found a good example for a word she wants to remember, and decides to send it to the database ("Word Stack 1") on her floppy disk. For the first entry, this involves telling the program where the disk is:
Each new word sent to the database opens a new file, and any number of examples up to 30k can then be added to the file. Here are the two "abouts" from the source texts in Figures 11.11 and 11.12:

The accompanying examples are the default full-sentence selections from the source text, but if they wish students can use the mouse to expand, shrink, or alter the context they send with a word.
Once a collection of words has been assembled in the database, a number of things can be done with it. Arabic script is accessible in a "definitions" field, so that students can enter a gloss in their native language. They can also add notes with the examples, or type in other examples from another source. The option of interest to most learners-as-lexicographers at this point is "Print," and a report form has been pre-coded into the stack to assemble the students' words, examples, definitions, or notes into professional-looking, two-column documents. To say that this feature has been used hard is an understatement. Figure 11.5 is a typical page that a student has produced, a substantial document considering it represents only a few clicks and a little typing.

Some points about Laila's glossary: First, related-word information has been noticed and included ("employ" and "employee.") Second, two senses of "engaged" have been noticed. Third, several possible Arabic translations have been entered for some of the words, suggesting that more than a one-to-one translation strategy or naive lexical hypothesis is being used. Fourth, most of the context sentences chosen are fairly clear illustrations of an important meaning of the word in question, with the possible exception of the sentences chosen for "employee" and "encourage."
To ensure that students do not print their entire list every time they add a few new words, "First Word Today" and "Alphabetize" allow the student to tell the report generator where to begin printing the current document.
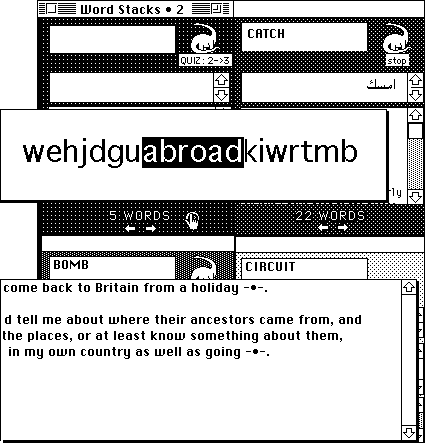
Amateur lexicography is not the only option. A set of further activities can be launched from the Word Stack that will give learners practice in recovering and recognizing their words, activities borrowed from PET·200 but now individualized for personally chosen words. Four further word stacks reside on the learners' disks, and can be accessed by clicking on the "Quiz" buttons. The object is to move the words from Stack One to Stack Five through activities of increasing challenge, in a computerized version of an idea proposed by Mondria (1993).
Here is the right side of the student's screen with the five word stacks opened:

The activity for moving words from Stack 1 to Stack 2 is a simple reconstruction of a gapped sentence. The headword and definition disappear, the entries are put in random order, and a menu-entry button appears. The headword is removed from each sentence the student has sent to the stack, replaced by the symbol "-·-". Holding down the entry button brings up a menu of choices:

A correct entry sends the entire data structure (word, Arabic gloss, examples) up to the next stack; an incorrect entry sends it down to the previous stack. The idea, well laid out by Mondria, is that the word in need of more practice gets it.
The move from Stack 2 to 3 is made through another PET·200 activity, distinguishing the word out of a jumble of letters:
The move from 3 to 4 is via spelling the word correctly, and once again the GUIDESPELL feature encourages the interactive reconstruction that was so popular in PET·200. In all these activities the learner will soon see that recovering the word is easier if more than one example has been sent to the database, so once again multicontextual learning is encouraged.
Unfortunately, the adaptation of PET·200 activities in PET·2000 does not extend to working with large texts. The loss cannot be avoided. Unlike the PET·200 user, the PET·2000 user is free to choose which words to work on from any number of source texts in the corpus, so it is highly unlikely that any single text could be found bringing together enough of these particular words to build a text activity on. Even if such a text existed, where PET·200 could search for usable texts from a total of 20, the PET·2000 corpus contains more like 250 making search time prohibitive.
However, the Stack 4 to Stack 5 activity makes up for some of the loss. Unbeknownst to the user, when a word and example were originally sent to Stack 1, another randomly chosen example of the word was also sent with it, to wait in a hidden field until needed. This ghost sentence rides with its data-set through the stacks. Then, on the move from Stack 4 to Stack 5 it appears, giving the student a novel context to transfer the word to. Here Laila is faced with a sentence requiring "abroad" that she has almost certainly never seen before (cf. Figure 11.18 above):

At the end of each stack, students get a score and are reminded of problem words:

They can go back and forth between PET·2000 and their Personal Stacks as often as they like, and they can quit Stack activities without completing them. They can send 20 words from the concordance and then quiz themselves, or pile up 100 words from several sessions and practice them all later.
On quitting PET·2000 learners are given summary information about their session. This information is, of course, just a drop from the dribble file. The next chapter examines dribble files in more detail.

The immediate motivation to use PET·2000 regularly is the weekly quiz, on the same format as the PET·200 quizzes except that items are sampled from a far greater number of words (the "C" quiz below samples 25 from 217 words); the spelling section has been removed (given the number of words involved); and the number of short-definition questions has been increased. The 12 weekly quizzes all have 15 short-definition questions and 10 novel-text questions (Figure 11.22). As in the PET·200 study, these quizzes have been designed to allow a comparison of two kinds of words knowledge.
A point to notice about this and all the other quizzes (in Appendix E) is that while only 25 "C" words are directly tested, many more appear in the text task ("credit," "change," "complain," "criminal," and so on.) Students who have learned their "C" words will have no trouble comprehending these ideas, or supplying words for the gaps:
- ... it wasn't easy to (7)........... these criminals because no one expected the thieves to be children
- Computer criminals have also (9)........... problems for credit card companies ...
The effect of this recycling is to test more words, as well as guarantee comprehensible contexts for the test items. The lexis of the all the texts has been 95% constrained to the 240 list plus the 2400 list as covered to date, with the aid of EspritDeCorpus.

PET·2000 provides motivation to use concordance software extensively. It is driven by a list of words the students know they need to learn; the tutor can be operated entirely by clicking the mouse; it allows for total individuality of instruction; the words of the corpus are 99% within the target zone; most of the texts are thematically familiar; the concordance information comes in a format minimizing mystification; there is plenty to do with the information gathered, from assembling a glossary to a wide range of practice activities. There is guidance for the weak, freedom for the strong. So, if concordance has any ability to simulate the rich lexical acquisition of natural reading, it should show itself here.
| contents |