
It might be expected that PET·2000 would appeal less to students than PET·200. The screen is more cluttered, there is less step-by-step guidance, there are no free definitions, and there is no control on the proliferation of word senses. Still, PET·2000 was about as popular as PET·200. Here is how 113 Band 3 students rated their course materials in May 1995:
Clearly PET·2000, the grammar book, and the PET practice tests (also in the Mac lab and developed by the author) were a cut above the other materials, as far as the students were concerned.
This popularity was achieved even without the supplementary text reconstruction activities described in the previous chapter, because these activities were not part of PET·2000 when the data discussed in this chapter was obtained. The data discussed below looks only at students' use of PET·2000 and the Word Stack without quiz options.
The PET·2000 idea was popular with students, but not necessarily with their instructors, some of whom had doubts about the underlying inductive learning theory. They argued against making students collect examples of word use, since the words could be better learned from a bilingual dictionary. The dictionary work could be facilitated, of course, if the students were given a computer-generated list of the 2400 words with spaces to jot down translation equivalents. Why not let students use PET·2000 to generate a simple wordlist, no complicated examples, if they wished? This would be the high-tech version of standard area practice and a perfect example of the "study skills" faculty deplore.
In fact, in the midst of the low-control scenario described in Chapter 9, these instructors' reluctance about learning from examples was the unwitting offer of a control group. If some learners or ideally complete groups went for the wordlist-only option, then they would be learning from dictionaries while the others would be learning from corpus and concordance (and dictionaries too, no doubt). This rough division would allow further testing for a concordance effect, and would replace the versioning methodology of the PET·200 study which was no longer possible. So the system was reconfigured to allow students to send words to their Word Stacks without examples to be printed as a wordlist.
The two groups thus created are admittedly self-selected. However, the dribble files reveal whole intact classes heading for one mode of use or another, suggesting a large role for instructor influence. And since PET groups are otherwise equal and randomly selected, there is at least some case for seeing these self-selected groups as useful groups for comparison.
The dribble files tend to be of two types. Figure 12.2 shows a "good learner" way of going about concordancing. "WD" indicates that a concordance has been requested for a word on the PET list; "¶" means that a source text has been requested for a concordance line; and "dB" means that an entry has been sent to the Word Stack. In 52 minutes, Sumaya has looked at 79 concordances, requested 77 source texts, made 91 database entries, and printed a report of her work.

Several points about the file may not strike the eye. First, Sumaya is not simply investigating every single word on the list. There are 179 "P" words, but she has selected only 79 for attention. A comparison between words available and words collected shows her passing by "page," "pain," "painful," and "paint," displaying some metacognition about what she knows and needs.

Second, although Sumaya goes through the list alphabetically for the most part, toward the end she goes back and reconsiders some words from the beginning (such as "particular"). Third, not every word sent to the database gets an example, for instance "prove." Fourth, she often sends several different examples for the same word, such as "point" "put" and "poetry," indicating that she is making use of the multicontextuality offered by the concordance medium. Fifth, not every word that gets concordanced is taken on to the source text stage; "per" is concordanced, then dropped, presumably because it was recognized when seen in context ("per cent"). Sixth, Sumaya notices the difference between "plane" and "plain" and "practice" and "practise," sending examples of each to her Word Stack.
The dribble file suggests that Sumaya is searching through the examples of each word before sending one to her database, at least where she sends several. In other words, she is not simply sending the first example mechanically, she is using the concordance to "negotiate input." To find out how much students generally were searching through examples, five of their glossary printouts were compared against the concordances that were available to them over a random stretch of the word list.
Figure 12.4 shows that there was a good deal of variation in how selective students were, which precise words they attended to, and which of the three or four examples they sent to their Word Stacks. In the table, "" means a word was sent to the database, and the number after it (" 2") refers to whether the accompanying example was line 1, line 2, etc of the concordance. Twenty of the 40 examples selected were the first concordance line, 14 were line 2, two were line 3, and one was line 4; three words had no example. Almost half the examples (17 out of 40) were other than line 1, suggesting a certain amount of discrimination in the choice of a clear example.

However, not all students spent time sifting through examples, such as Nabil whose work is shown in Figure 12.5. The pattern here is clicking on words in the PET list and sending them to the database for printout, as a wordlist without examples. Chances are good that Nabil is taking part in a "cooperative learning" project in which a group of male students take turns generating the week's wordlist which they will then photocopy, ready for annotation with Arabic synonyms. However, Nabil is not using PET·2000 entirely mindlessly; he is exercising at least some metacognition in selecting a listing of only 127 "P" words, when 179 are on offer.

(Some long words like "particular" have been edited to save space.)
Pulling the important patterns out of 1356 dribble files (113 students x 12 weeks) would be a monumental labour by hand, so once again a computer program was written to aid with data analysis. SHRINK (Cobb, 1995b) assembles the students' dribble files, sorts them into order, extracts summary information, and searches for specific patterns. Figure 12.6 shows SHRINK summaries of Sumaya and Nabil's PET·2000 work for the entire term.
The top horizontal line is the number of words selected for any sort of treatment, then the number of source texts requested ("¶" because about a paragraph in size), and then the ratio of source requests to words. The second line records how many source texts were requested in the first, second and final months of the term, to check for persistence and trends. The third line records the number of sessions, time on task, and calculates averages. The fourth line records the number of database entries the student has made, and calculates the ratios of both database entries to words examined (Is the student sending every word examined to the database?) and database entries to source texts requested (Is the student sending examples to the database or just words?)
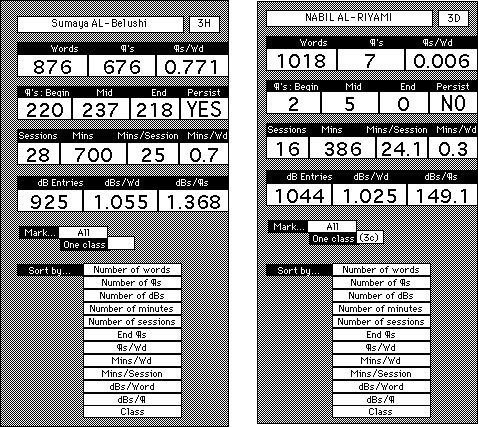
A wealth of information lies within the 113 such analyses collected, only a small portion of which can be examined in detail in the present study. One piece of information that may not be obvious is that since Sumaya has read 676 source texts of roughly 150 words each, then she has read more than 100,000 words (150 x 676 = 101,400) in the term, almost certainly more than she has read in all her other courses put together. This can be informally confirmed by looking at typical SRA (Parker, 1985) reading lab records: few students can force their way through more than 10 stories of about 1000 words each over the length of a term, just 10,000 words total. So even if concordance is shown in the end to have no special way of making vocabulary learning efficient, it may still be an aid to learning in the old inefficient way where massive reading was the key ingredient.
How many students read a lot on PET·2000? SHRINK shows that about one-third of the students (49 of 130) used the program hard as a source of reading, 100 or more paragraphs, although there is no control on how much reading took place when students worked two to a computer (as they often did, working out the meanings of words in lively Arabic discussions), and when they looked over each other's example print-outs before the weekly quizzes.
SHRINK can group the records of intact classes, and then sort the individuals in the class by any of the fields in the database. In Figure 12.7, a good-user class is sorted below first by the number of words selected for attention (i.e. concordance and/or sending a word to the database for printout), and then by the number of source texts requested. The main revelation of this class-by-class analysis is that most members of intact classes tended to use PET·2000 in the same way, suggesting as discussed above a strong role for teacher enthusiasm in selling the concordance idea.

Table 12.1 shows the total number of source texts requested by each student, each request presumably reflecting a desire to clarify the meaning of a word contextually (since a word can be sent for list-printing without it).
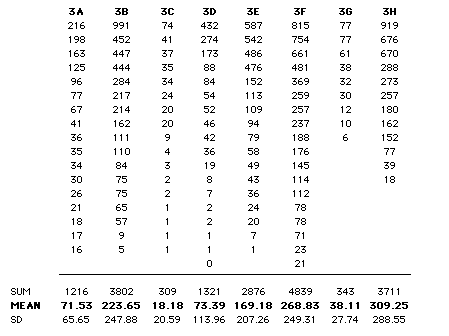
Although of course there is variance within classes, the huge between-class variance (significantly greater than chance) clearly reflects the way PET·2000 was being promoted in the classrooms. Classes "C" and "G" were not encouraged to use the program, other than to generate easy wordlists, while "B," "F" and "H" clearly were. Table 12.1 is almost a textbook illustration of the role of teacher support in the implementation of a new technology.
"C" and "G" will be used as control groups in two studies below and "F" and "H" as experimental groups. Two studies are needed because in this data there are two levels of students. Groups "A" to "F" were composed of students fresh from Band 2, while "G" and "H" were remedial students who had already been through Band 3 once and narrowly failed to reach Band 4. The main difference was that the remedial groups "G" and "H" were higher in terms of starting vocabulary size. Looking at two levels will allow a check on whether PET·2000 is more suitable for a particular stage of learning, and check for a convergent finding.
Did all this searching for examples, say in the case of classes "F" and "H", produce any benefits? According to the hypothesis, students who take the trouble to examine a word in several contexts should do better on a large-text task than those who merely learn words through short definitions, although not necessarily on a definition-based task.
All Band 3 students were pretested for vocabulary in March 1995 and posttested in May, two months later. Two months is not a complete term, but in 1995 the winter term began in February, during the Muslim month of Ramadhan, a time when students fast and stay up late, possibly compromising the reliability of pre-test data. So although students had used PET·2000 during February, pre-testing was delayed until March, so that scores were probably a little higher than they would have been otherwise, and learning gains were produced over only a two-month period. The pre-post test once again had two parts, intended to measure two kinds of word knowledge, the Word Levels test for short definitions, and a task fitting words to a novel text (in Appendix D).
Normal (non-remedial) groups "C" and "F" were found in pre-testing to be statistically equal on two measures, overall Levels Test mean 65.2% (SD 14.8), and novel-text task mean 60.1% (SD 19.2). With a mean score of 65.2% on the Levels Test, or about 1300 words, both of these Band 3 classes had members at risk in terms of the 30-50-70% success baseline.
Control Group "C" mainly used PET·2000 to generate wordlists and annotate them with Arabic translations. Table 12.2 shows the number of words and then source texts requested by individuals in the control and experimental groups.

These are clearly two distinct groups in terms of how they used the tutor: the control group "C" requested fewer than one-tenth of the source texts requested by the treatment group "F."
Here are post-test mean scores for the two tasks (the Levels pre-test mean was 65.2%, and the text-task mean was 60.1%):

On the Levels Test, both groups made significant gains over their pre-tests, about 7% gain for control group "C" (representing about 140 new words) and 9% gain for experimental group "F" (180 words), but not significantly different from each other. But in terms of the ability to use the words they learned in novel contexts, "C" made no significant progress (from 60.1% to 62.76%, n.s.d.) while "F" rose from 60.1% to 74.1%, a difference greater than chance compared to both their former selves and the control group (F=3.46, p<.05). Figure 12.8 presents this information graphically.

This is the predicted outcome, and the exact finding reported in Mezynski (1983), that learning words by definitions has little effect on comprehending the words in novel texts. So it appears that some of the benefits of natural word learning are taking place for students who use PET·2000 as directed, but in hours rather than years. Students in the experimental group learned almost 200 words to a fairly high level of comprehension in just two months, with an average time-on-system of 6 hours (SD 2.18 hours). As a very rough yardstick of comparison, Beck and colleagues' (1982) training program needed five months of classtime to teach 104 words up to comprehension level.
The groups in this experiment are control group "G" (a group making almost no use of PET·2000's corpus) and experimental group "H" (a group using it a great deal). These are both remedial groups, who have already spent a term in Band 3 and whose year for clearing the English requirement is nearly over. It is primarily such high-risk students whom the lexical tutor has been designed to help, yet at the same time they provide quite a stiff test for it.
These subjects are already at a relatively high level of vocabulary, testing 76% on the Levels Test (compared to 65% for the non-remedial groups in Experiment 1). Also, they are more concerned than other Band 3 students about academic courses (commerce, accounting, information systems, etc) , since they are moving ahead with their cohort in spite of their PET problem. They almost certainly feel that learning general English is no longer a priority. On the plus side, however, these students are in a serious time squeeze and might see self-access options as attractive.
"G" and "H" were found in pre-testing to be statistically equal on both measures of word knowledge, Levels Test mean 75.7% (SD 10.8), and text task 71.0% (SD 12.2). "G" was one of the groups who used PET·2000 as a wordlist generator. Table 12.4 reviews the numbers of PET·2000 source texts requested by individuals in these two groups.
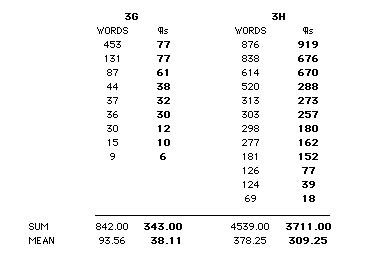
In fact, group "G" did not even use PET·2000 much as a list generator, but their instructor reports that somehow the students all had well-annotated lists on quiz day.
The result after two months is similar to the result in Experiment 1. Here are post-test mean scores for the two tasks (the Levels pre-test mean was 75.7%, and the text-task mean was 71.0%):

The pattern is remarkably similar to Table 12.3 in Experiment 1, except a level higher: no between-group differences in the Levels Test, but significant differences on the text task.
On the Levels Test, experimental group "H" has progressed from 75.7% to 79.9% (SD 13.3), and control group "G" from 75.7% to an almost identical 79.6% (SD 12.8), a between-group difference no greater than chance. But on the text task, the experimental group mean has risen from 71.0% to 86.8% (S.D. 8.9), the control group mean only from 71.0% to 77.0% (SD 10.7), a significant between-group difference ( t=2.4, p<.05). Figure 12.9 represents this pre-post information graphically.

Experiment 2 replicates the main findings of Experiment 1. The only difference is that in Experiment 2, the pre-post differences on the Levels Test are not greater than chance for either group (F=0.22, p>.05, for the common pre-test mean and two post-test means).
The lack of a gain on the Levels Test could be due to a ceiling at the 2000 level for these relatively advanced students, four of whom in each group had pre-test scores in the 80s. Still, with a null gain it is hard not to wonder whether they might not have been wasting their time on PET·2000. This impression of time-waste is strengthened when one looks at the weekly quiz means for the experimental group, which are consistently high and suggests a task too simple for these students (who perhaps should have been working on vocabulary beyond the 2000 level):
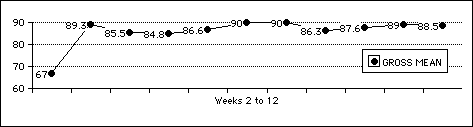
There are no significant differences in this data (except between weeks 1 and 2, when the students were deciding whether to take the activity seriously). However, when the data is carved up by different measures and individuals, the picture gets more interesting.
First, looking at measures, when the weekly quiz gross means for the experimental group are split into definitional and text components, a trend emerges:
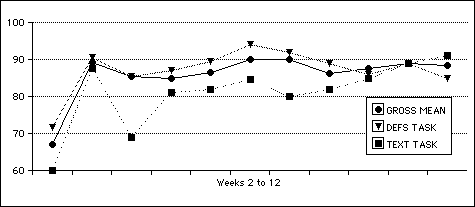
After the class has settled to the weekly quiz idea, there appears to be a gradual crossover from skill with definitions to skill with novel texts. It is tempting to see in this a shifting emphasis from memorizing static meanings to seeking out dynamic conditions of word use. The idea is interesting, but few of the distinctions in this data are significant.
However, looking at individuals and sub-groups within the data, as disclosed by the dribble-files we find some distinctions that are both interesting and significant. Here are the individual scores behind the no-gain finding on the Levels Test for the experimental group, ranked by the number of source texts (¶'s) requested on PET·2000:

The experimental group in fact contains two distinct groups, in terms of both program use and vocabulary gain, divided fortuitously into sub-groups of six each, and interestingly also by gender (although with one exception in each direction, Wa'el and Salwa).
These two groups form another almost perfect comparison set. The Levels pre-test scores are virtually identical (female mean 77.0%, male 76.8 %), as are the text-task pre-test scores (female 70.0%, male 71.0%), while the number of source text requests is five times higher for the females (t = 3.45, p<.05), as shown in Table 12.7.

For these two groups, divided only by mode of use of PET·2000, the Levels Test pre-post difference is significant: From a common mean of 77% (S.D. 10.9), the female group has advanced to 90% (S.D. 9.64), while the male group has declined to 69.5% (S.D. 5.82), a terminal difference of over 20% on the Levels Test, representing in real terms a difference of 400 words (significant at p<.05, F=4.94).
The male students appear actually to have lost definitional knowledge they once possessed. The irony is that if the males were not using the corpus they were almost certainly using a purely definitional strategy for acquisition, as is also suggested by their dribble files.

The loss pattern appears to be real, since it survived a replication. In a surprise retention test, a random weekly quiz was re-administered in April 1995 six weeks after it was originally administered in February, and the same effect was found:

For males, definitional knowledge of words they knew six weeks ago has declined, from 87.6 to 75.6 (s.d.), while their contextual knowledge has stayed the same (78.3 to 81.7, n.s.d.) For females, there are no losses, and although gains are not statistically significant this seems an artifact of a ceiling effect. Figure 12.13 presents this information graphically.

These differences are interesting, but the main difference between the male and female groups lies in scores on the text task in the weekly quizzes. In Figure 12.11 the in-class quizzes were divided for definitional vs novel-text tasks; and now the text task is further divided for male and female contributions. All differences are significant except weeks 2, 5, and 11 (75% of the time).
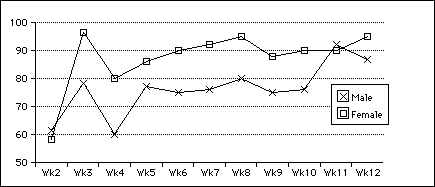
The finding seems clear: learning words from texts enables students to comprehend them in novel texts; learning words from definitions does not aid comprehension, and the definitions will probably be forgotten as well. Students still have a lot to learn about words after they have learned to match them to short definitions, and corpus work for these students was almost certainly not a waste of their time.
It seems clear that meeting a word in several contexts, whether slowly in natural reading or quickly in a corpus, enables a language learner to comprehend the word in novel contexts. These female students (and one male classmate) are acquiring word knowledge of a quantity and quality normally the result of years of reading or months of intensive instruction, but with an average time expenditure of less than 10 hours--give or take an hour and a half.

| contents |