
Looking at the MicroConcord interface in the light of the learners and tasks discussed above, one sees how improbable it is that SQU students would get much use from the interaction it proposes.
Any of the advantages of concordancing hypothesized in Chapters 2 and 3 could in principle be gained by using MicroConcord, but there are some reasons that extensive use of the program by first year SQU students is unlikely. The interface requires complicated keyboard entries. The corpus is authentic samples of academic text and quality-press editorials (admittedly it can be simplified). But the most serious problem, pedagogically, is that once a mass of lexical information has been delivered to the screen, there is nothing further for an unsophisticated learner to "do" with it. Not surprisingly, an informal poll of SQU language instructors showed that most of them saw student concordancing as impossible for learners at any but the highest levels.
However, MicroConcord is not the only possible interface for a concordance program. The proposal here is that the corpus-concordance concept can be adapted to less sophisticated tasks and learners through interface and corpus design. For example, keyboard entry can be made unnecessary to launch searches; little meta-language might be required to get across the idea of multiple contexts; a corpus could be assembled that was roughly within the learners' zone of proximal development, and yet still authentic (i.e. not set up to illustrate specific points); and things can be found for learners to "do" with the fruits of their corpus searches. This chapter will show how these design ideas were realised in PET·200.
PET·200 is a vocabulary training system that attempts to incorporate all of the foregoing pieces: to link with the students' prevailing definitional strategy, build on the tradition of text reconstruction at SQU, give Band 2 students a start on the 2400 wordlist, and prepare them for more open concordancing in Band 3 with PET·2000.
The tutorial presents Band 2 learners with 240 new PET words, 20 words a week for 12 weeks, tested off-line weekly in the classroom. The target is to bring a learner with the Band 2 average of 600 words up to 800, a size-gain of 33%. Each 20 words can be practiced through up to five types of text-based activities, meant to replicate in some measure the extensive recycling and re-contextualizing of words that characterizes Beck, Perfetti and McKeown's (1982) "rich" in-class training program. But more than double their 104 words will be attempted in half the time, a considerable gain in efficiency if the results were comparable. The five activities can be accessed in any order, and choices are offered at all decision points, so that learners can only use the program by taking some role in the design of their own learning.

The best way to proceed is to describe and depict the tutorial, jumping between user level and program level as needed, picking up design and learning issues along the way. When the learners boot the program, they meet an introductory screen that indicates the alphabetical range of the wordlist of the week, previews the five activity types, and waits for a name to be entered:

To get reliable user data, the system does not allow students to enter their names with various misspellings etc but rather asks them to indicate on a menu who they are and which class they are in. They are told that the computer keeps a record of what they do, and that their language instructor has access to this record (but they also know this information cannot be used against them since only the PET determines their success or failure).
When the name is properly entered, five buttons appear allowing the student to go to any of five activity types-for example allowing Part 1 to be completed on Monday, Part 2 on Tuesday, and so on. The idea is to maximize use by making the system as flexible as possible.

In Part 1, the week's 20 words come through the interface one at a time in random order (Figure 8.5). The learner can listen to a digitized recording of each word by clicking on it, and in the black window at the bottom of the screen there is a small concordance for the target word culled at run-time from a corpus of 20 PET-level texts. In the centre window there are four brief definitions culled from a small database of the current 20 words, one of which is correct and the others randomly selected. The task is to use the concordance information to choose the correct definition.

Each concordance line is actually triple the length shown here, and more context can be accessed via the slide control at the bottom of the window or by the arrow keys. The activity of choosing a meaning for the word is intended to simulate encountering a word several times in natural reading and inferring an integrated meeting for it, but with less hit and miss.
Take a detour into system design and architecture for a moment. The corpus is normally invisible to the learner but accessible to the program, as is the word database that provides the words, sounds, and definitions. Figure 8.6 is a typical text from the corpus. The texts are all from either old or practice PET tests, or from lower intermediate course books, and the students will have seen many or even most of them before. They were assembled on the basis of rough level, PET-typicality, and topic appeal. "Solar Pump" in Figure 8.6, from Oxford's (1984) Exploring Functions, has been chosen for its likely interest to desert dwellers in a developing country. The texts are "authentic" inasmuch as they have not been manipulated to make contexts particularly "pregnant"; learners must search through raw albeit scaled text for contexts that are clear to them.

The word databases, also invisible to the learner except in a brief fly-past as the program opens, carry the words, brief definitions, and soundbytes.
The database loads into memory and then proceeds to open the corpus stack and finally PET·200 itself, which of course is independent of any particular corpus or wordlist.
There are two possible ways of supplying PET·200 with its words and matching corpus. One would be to choose 240 words from the PET's 2400, deemed more important than the others for whatever reason, and then find or write texts to illustrate these. This would be very much a hand-coding approach, as criticized in Chapter 3, and likely to verge in the direction of pregnant contexts. Since enough of such texts would be difficult to find, they would probably end up being composed by instructors specifically to explicate the target words. Another way would be to start from a corpus of texts within the learners' range and interests, and find PET words unlikely to be known to the students. The second way is closer to the temper of corpus linguistics, and was adopted.
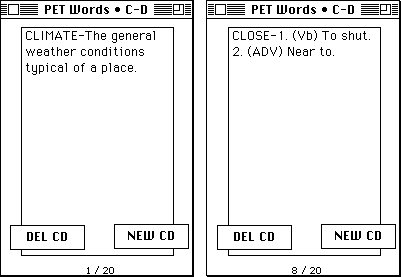
The method was as follows: 20 machine-readable texts were combined into a corpus; a concordance program extracted a frequency list and matched it against the PET list; from the matches, 240 words were chosen that occurred at least four times in the corpus and were unlikely to be known by the students. No hand-coding or corpus-rigging was required. Of course, hand coding was required to provide a definition for each word selected. Each definition reflected the particular sense of a word as it occurred in this particular corpus. How was polysemy handled? Whenever a word appeared in two senses, as in the case of "close" in Figure 8.7, a dual-sense definition was written to reflect the two senses present in the corpus.
Why present the words in alphabetical lists? The normal way of presenting new vocabulary items is semantically related groups. However, there are two reasons for choosing alphabetisation, one related to system design and the other to learning design. First, system design: these words are eventually to be used in gap-filling activities in Parts 4 and 5 of PET·200, and a well-known problem with such activities is that two words often fill a gap equally well. CALL folks normally see no way around this, except to make learners privy to the secret that computers do not really know language, they merely match strings. However, an interesting insight that emerged from the design of this software is that when a gap-filling routine is driven by an alphabetical wordlist, the two-good-words problem never crops up. Words close together alphabetically are sometimes related but rarely synonymous. "Certain" and "certainly" will never contend for a gap, while "certain" and "sure" may.
Second, learning design: research has shown that counter to intuition, words are better learned in random groups than in meaningful groups (Higa, 1963; Nation, 1990; Tinkham, 1993). The fact that words eventually to drift into semantic groups in memory does not imply that they should be learned that way, i.e. that they should be initially encoded in their terminal configuration. It is well known that similar items interfere with one another in the encoding process. Alphabetization is a simple, computable way of producing lists of semantically disparate items.
Back now from system to user: In Part 1, when the learner has chosen a definition, he or she is either told it was correct, or else the incorrectly chosen definition simple disappears from the screen.

In Figure 8.8, the learner has chosen correctly, and is prompted to request another word. When the words are used up and errors recycled, the system proposes Part 2, though in fact users can move anywhere any time.
After Part 1, the learner meets no further definitions. The soundbyte and the concordance-now with the keyword blanked-provide the information on which choices are made. In Part 2 (Figure 8.9), the 20 words again come through in random order, and this time the task is to pull the target word out of a random jumble of letters (adapted from an idea in Meara, 1985). The learner drags the mouse across a group of letters, and on release finds out whether the word was correctly identified.

The hope is that the learners will pay some attention to the concordance lines as they try to listen to the word and find it on the screen. (Whether they do or not is the subject of Chapter 6.) If the answer is correct, only the word and a large check-mark remain in the centre window, and the concordance lines are filled in for contemplation.

In Part 3, the 20 words are once again recycled in random order, and this time the learner is asked to type the correctly spelled word into the centre window. A feature not visible in Figure 8.11 is a routine called GUIDESPELL, that helps learners shape an answer incrementally. For example, if the target word is "certain" and a learner types "certin", GUIDESPELL will indicate how much of the word was correct-i.e., will back-delete to "cert" for the learner to try again from there, as many times as necessary. Most commercial CALL software, by contrast, insists binary-fashion on fully correct entries. Some recent artificial-intelligence approaches allow fuzzy matches. But neither of these alternatives allows a cumulative test-and-generate interaction as GUIDESPELL does.

Figure 8.11 shows the feedback following an attempt to enter "charge" as "chrg". The system informs the learner that the string up to "ch" was correct, incidentally reminding a speaker of (unvowelled) Arabic that English writes its vowels.
In Figure 8.12, the learner has gone on to enter the correct spelling.
Parts 4 and 5 change the language focus from words to texts, and the cognitive process from recognition and recall to transfer. The assumption is that if the 20 words have been learned well, this knowledge should be transferable to novel texts. In Figure 8.13 the system has found five texts using C-D words, and deleted these words for the learner to replace.

Text from Exploring Functions (OUP, 1984).
The learner goes through the text filling in the blanks (bullets) with contextually appropriate words from the standard drag-and-release menu.
The program has quite a lot of work to set up text activities for 12 word lists and twenty texts. Its first task is to find some texts that contain a suitable number of the user's current words. When the user begins either Part 4 or 5 for the first time, PET·200 goes to the corpus and ranks the 20 texts by the number of occurrences of the 20 target words present in each, discarding texts below a certain minimum. Then, it further ranks the remaining texts by how many of the target words are repeated more than three times. Texts with many repetitions of the target words are reserved for Part 5, the rest are used by Part 4 (normally about five or six texts of about 250 words are dedicated to each).
Three design points should be noted in Figure 8.13. First, while the text is novel, the learner has already seen the contexts for many of the target words in the form of concordance lines. The principle is that concordance lines should be seen to source back to larger texts, and that "massed" concordance information should always be linked to "distributed" natural occurrences. (So this is transfer of word knowledge to comprehension of a novel text only up to a point.) Second, the interaction is entirely mouse-driven, on the principle that learners are already dealing with a larger unit of text than they are used to, and every attempt should be made to focus on only one operation-not make them struggle with keyboard entry when they are already struggling with voluminous (in their terms) text. Third, the pull-down menu will drop from any point on the text window, so there is never a problem of obscuring the very context that should be the basis of an answer.
In Figure 8.14 a learner has successfully entered "common" and is about to grapple with "collect." The various types of feedback and trail-marking are evident in the illustration.

The HELP available is a concordance of further examples of the needed word. In Figure 8.15, a learner searching for "certain" might be cued by some of the other occurrences of the word that have been seen before.

Part 5 is like Part 4, except that the entry is by keyboard, random sequence is possible, and there is a high degree of repetition in the target words.

The learner looks at a context like "The dog chased the $$$," decides on a text string hidden by the dollar signs, types it, and presses <ENTER>. Any correct part of the string "goes in" (replaces dollar signs in the text).
Keyboard entry is meant to make the activity more difficult, in the sense of productive rather than receptive. The word for each gap must be recalled rather than chosen from a list, leading to a type of processing on the borderline between reading and writing-or "reading as writing" as discussed in Cobb and Stevens (1996).
Yet keyboard entry also makes the activity easier-technology support for the upgrade in cognitive difficulty, in line with "cognitive tools" theory. Because of the GUIDESPELL feature, any correctly entered string will fill in matching strings throughout the text, so that repeated words need only be entered once. A single good entry can yield an enormous harvest of information that may be useful in further choices. This means that although the text is large, it can be reconstructed fairly rapidly. This is the point of dividing texts into high and low amounts of word repetition. (Many CALL activities look like this one, but have fewer repeated items or do not allow multiple matching, and can bog learners down for hours-or, more likely, inspire a premature bail-out.)
Figure 8.17 shows two of the interactive support features that make a long text tractable for this level of learner. First, the learner is piecing together the reconstruction little by little with the help of GUIDESPELL. "Day" has gone in, although the full answer is "days" (incidentally focusing the learner's attention on the syntactic as well as semantic requirement of the gap). Second, PET·200's routine for selecting words for deletion is intelligent, to the extent that if "day" or "deliver" is in its list of target words, then "days," "delivers," and "delivered" are included-by computation, not hand coding.

As in Part 4, when a text has been fully reconstructed, another text is ready if the learner wishes it. This is more word practice than many learners desire or have time for; the principle is that there should be more text and practice available than even the most enthusiastic learner has time for, so the tutor is never the limiting factor.

At any point in the tutorial a student can close the session, as Zuwaina has done in the middle of a Part 5 text reconstruction (Figure 8.18). The tutor reminds her that it has a record of roughly what she has done in the session. In fact, there is an extensive record of her endeavours on the computer's hard disk, which can be viewed during a session if desired as shown in Figure 8.19. The dribble file records which activities Zuwaina chose, how many attempts she put into every correct answer, and whether she completed one activity before moving to another. When she exits PET·200, her time-on-task is calculated and the whole protocol file sent to her folder on a network server.

The students are free to use or not use PET·200 as they wish, but they are required to take a vocabulary quiz in the classroom once a week, about half of whose items are drawn from the 20 "computer words" (as students call them). The rest are drawn from the vocabulary offering of other courses the students are taking. The reason for including words other than computer words is to allow a comparison between words learned through PET·200 and words learned by other means (to be discussed in Chapter 9). These quizzes all follow the same format: there are six words to spell from dictation, six short definitions to match words to, and a novel passage with eight gaps to fill. Figure 8.20 shows the "C" quiz as an example (see Appendix D for the complete set).
Some points about these quizzes that may not be obvious: First, the meaning-recognition section (Part 2) is the same format as Nation's Levels Test, so that the students are not confused with endlessly switching formats. Second, the deletion passage (Part 3) is a text the students have never seen before. Third, the words surrounding the gaps in the passage are carefully selected to be words the students are likely to know, reducing the chance that an error would involve unknown words in the contexts. Finally, a comparison of results on Parts 1, 2 and 3 of the quizzes should allow some assessment of different depths of word knowledge, orthographic vs definitional vs transferable word knowledge.

The weekly quizzes were a good motivator for the students. Going to the
lab to learn their 20 words quickly became part of their routine-two to
a machine the day before the quiz. The quizzes ensured that PET·200
was tightly integrated into the curriculum soon after its introduction.
A large supply of data has been generated by students using PET·200,
mainly during the winter of 1994. The students were pre-post tested with
both the Levels Test and an in-house test; their dribble files fill several
computer disks; and their weekly quizzes track three kinds of word knowledge.
Some of this information will be used to answer two questions in the next
chapter: Did the students learn words from the tutor, compared to some other
ways at their disposal? And did they learn from the concordance feature
specifically?
| contents |