
In its decade of existence, the Language Centre at Sultan Qaboos University has seen a good deal of scholarly activity. A sample of publications is Fahmy and Bilton (1989), Griffiths (1989), Cobb (1989), Stevens (1988), Flowerdew (1993), and Arden-Close (1993). A perusal of the titles, however, shows that these studies deal with program development, instructional design, teacher talk, or student strategies, but never with measuring students' learning in relation to the instruction they receive. This omission is now being addressed (Horst, 1995; Stevens, 1995; Cobb, 1995a).
There are some reasons for the omission. One is that the endless re-shuffling of curriculum kept the Language Centre busy producing rather than evaluating instruction. Another is that most language courses at SQU are lockstep courses delivered to several classes at the same time, so that separation of control and treatment groups is impossible. Another is that classes have not been grouped by ability, so that most instruction has been rough not fine tuned. The research to be described here faces these constraints and looks for ways around them.
The PET has made it easier to do research at SQU, in some ways. It has provided a clarity about objectives (such as learning the 2387 words) against which progress can be measured. It has put students into cohesive classes, and generated standardized pre-post information. However, instructors and researchers do not have access to that information in the form of raw scores, but only to pass-fail data, so additional measures must be devised if smaller learning increments are to be charted. Also, the problem of control groups has not gone away. There is simply no possibility of comparing different ways of getting students through the PET, because all resources must be devoted equally to the success of everyone. Various ways of getting around the control problem are proposed below, none of them 100% watertight but some of them capable of providing useful information.
The learning effects of PET·200 will be examined in three phases. First, did the students use the system to any extent? Second, did they learn any words? And third, can any of the learning can be traced to concordancing?
As with LEXIQUIZ, it seems that students liked learning words with a computer. In the College of Commerce, students are regularly asked to assess the instruction and materials they receive, and Figure 9.1 shows the materials evaluation for an intact class of 11 students after using PET·200 for a term. Points to notice are that PET·200 has beat out the published materials, even the traditionally prized grammar workbook and another vocabulary course called A Way With Words (Redman and Ellis, 1991).
The dribble files show that many students used the program a lot, and used many of its options especially the soundbytes. They tended to work very hard on Parts 1 to 3, less on Part 4, and still less on Part 5. Particular favourites were Part 1 (choosing a definition from examples) and Part 3 (interactive spelling with GUIDESPELL). Some students became so adept at rapid interactive spelling that the program had to be redesigned to keep up with their speed requirements (this in contrast to the foot-dragging when the same students were made to practice keyboard skills with Typing Tutor!) No student declined to use the program entirely, even though it was entirely optional. Students not wishing to use the program could easily have copied the 20 words and definitions from their friends before the quiz, if they had perceived PET·200's concordances and practice interactions to have no value.
The dribble files also show students beginning to develop independent learning strategies, in line with the faculty members' hopes about how self-access would feature in the new college. Students always started with Part 1, where they got the definitions (which they invariably wrote down on paper). However, after that there was some variation. They often did Part 3 (spelling) then returned to Part 1 for review. Some repeated the spelling part over and over until they had no errors. Most avoided the larger text activities, but some did nothing but text activities. The main point is that students adapted the tutor to their own uses and fit it into their timetables.

Figure 9.2 shows a sample dribble file from a single session, extracted from the session by methods discussed in Cobb (1993c). This is a long session, 69 minutes, while the average was more like half an hour. However, although students chose different amounts of time to stay on PET·200, amount of use as indicated by number of lines in the dribble files did not decrease over time but increased slightly.
Points to note in the dribble file: First, Abdullah is choosing what to work on. Where the file says PART 4, this means he completed Part 3 and was sent to Part 4; but where it says JUMPED TO PART 3, this means he decided to leave an activity uncompleted and choose another. Second, Abdullah is making lots of mistakes. The large number of X's in the second column represents the interactive GUIDESPELLing discussed above. Third, he is doing a lot of text work. He did the paragraph work in Part 4, reconstructing four of the six paragraphs available. He jumped from Part 4 to Part 5, decided against tackling the dollar-signs, thought again, and went back to complete two texts. In 69 minutes, Abdullah entered 150 correct answers in over 300 interactions.
This student is using the system hard, but is he paying any attention to the concordance or just following a blind generate-and-test strategy? One slight indication that the concordance is getting some attention is the presence of "L" and "R" codes in the file indicating that he has pushed the concordance window to the left or right in order to get more contextual information. Other indications of concordance-attending are discussed later.
The amount of information contained within 2000 protocol files is enormous, unexpectedly so, and other than checking a sample for trends it is not simple to know what to do with it. Others have noted this problem, for example Goodfellow (1995b):
The capacity of the computer to record [the data that is produced when a language learner interacts with a CALL program], tracking keystrokes and mouseclicks, logging information given and received etc, far outstrips our current capacity to analyze this data and decide how best to use it (p. 1).
The PET·200 dribble files are a simple descriptive record of everything the student did, as befits a pilot project. Ideally, however, protocol data collection is focused in advance on the testing of a hypothesis, a point to be kept in mind in the development of the next tutor. In the meantime, one use of these files is to let their size in bytes indicate extent of program use (more revealing than time logs), producing a figure that can enter into statistical analysis. This use of the dribble files will be explored below.
Did the emphasis on vocabulary result in any general increase in students' vocabulary sizes? Nation's Levels Test will be used here as one of two pre-post measures, although it should be noted that PET·200 was not in any way set up to teach the exact words on this test, so the information yielded by this test pertains to general vocabulary growth. The test group is a remedial group (n=11) chosen because at-risk students are the main ones targeted by this treatment, and because a group stranded between one PET band and another is a maximally cohesive group. This group had just failed to clear PET Band 2, and size testing had classed them an effective Band 1 group in vocabulary by the usual 30-50-70% progression (Table 6.2), with a mean vocabulary size of 33.5% (SD 6.5), or 670 words.
But in less than three months the group mean had grown from 33.5% to 55% (SD 10.5), or 1100 words, exceeding the Band 2 norm. By this measure, these students learned on average (1100-670=) 430 words in one four-month term, which is both in the target range required by the PET and more than double the European norm (275 new words per six-month term as calculated by Milton & Meara, 1995).

Looking at individuals in Figure 9.3, some students seem to have almost doubled their 2000-level word stocks, for example S1 has gained almost 40% of 2000, or 800 words. Seven of the 11 students have made gains of more than 20%, or more than 400 words. While there is no claim that all these words have been learned by using PET·200 (the program does not even present as many words as some students have learned), there is a modest correlation between the amount of work students did on PET·200 as indicated by the size in bytes of their cumulative dribble files and their gain on the Levels test (Pearson product moment coefficient, r=.35).
A second, in-house pre-post test was administered along with the Levels Test to gain specific rather than general information. Forty specific to-be-taught words in the 2000 range were also pre and post-tested, 20 by short definitions and 20 by placing words in two novel texts (Appendix B). The mean pre-post differences were even more striking, as might be expected with a test of words actually taught. The mean had risen from 37% (SD=6) to 67% (SD=14), a gain of 30%.

Figure 9.5 is the in-house picture in terms of individuals. The correlation between program use and text score gain is r = .54, higher than the correlation between program use and the Levels Test (r=.35).
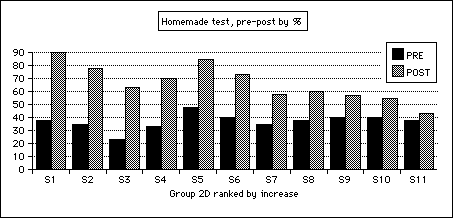
But are words being learned better, or at least as well, through PET·200 as in the classroom? In order to get some rough idea of this, the 12 weekly quizzes (Figure 8.2; Appendix C) were written to contain words learned from both the computer and from two courses with vocabulary components that the students were taking at the same time (Way With Words, Redman and Ellis, 1991, and We Mean Business, Norman, 1982). Both these courses present their new words in a list at the end of each chapter, and the students knew that some of these would appear on their weekly quizzes along with PET words. So this allowed a rough comparison between words learned in two different ways.
However, the number of words and the way they were taught in the classroom could not be controlled, so no precise comparison is intended and the data is purely exploratory. In any event, no claim is made here that CALL can teach words better than they are taught in a classroom, only that it can teach them about as well but more efficiently.
The tests track three levels of word knowledge-definitions, spelling, and transfer. The computer tutorial seems to have advantages over the classroom for spelling and transfer, but not for definitions. First definitions: the weekly quizzes contained a total of 792 short-definition questions (six questions per test, 11 students, 12 weeks). Of these, 391 questions pertained to classroom work, and 401 to computer work. The subjects' success with classroom words was 280 correct for 391 gaps, or 71.6%, with PET·200 words 290 correct for 401 gaps, or 72.3%.
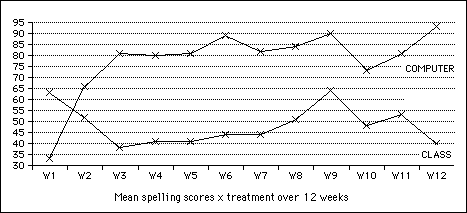
Second, spelling: as mentioned above, students used PET·200 a good deal to help them learn spellings. When the spelling-words on the quizzes are traced back to their learning sources, the mean spelling score over the term for the 11 students is 48% (SD 8.7) for classroom words, and 78% (SD 15.9) for PET·200 words (p<.05). Figure 9.6 shows this difference week by week.
Third, transfer to a novel text: a similar but weaker version of the spelling pattern obtains when the right and wrong answers are traced back to where the words were learned. The weekly quizzes contained a total of 646 gaps requiring classroom words, and 621 requiring computer words. The subjects' success with classroom words was 381 correct for 646 gaps, or 59%, with PET·200 words 422 correct for 621 gaps, or 68%. The two comparisons are depicted in Figure 9.8.
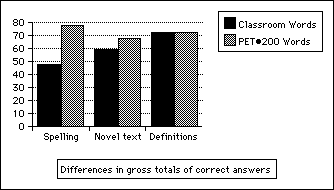
It is not worth the trouble to trace this information down to the level of individual testees or even tests, because as stated above the comparison of class vs PET·200 words could not be controlled for either number of words taught or instructional method in the classroom.
However, it was possible to control for whether concordance was having any role in producing the 68% success rate on the text task. Given the difficulty of separating control from treatment groups in the SQU setting, it was necessary to set up a control comparison within the program itself, through a strategy known as "versioning" (discussed by Malone, 1981). PET·200 was coded so that there were effectively two versions of the program residing together, one giving the students concordances and the other not. The program could be branched to either version by the designer or operator, but not the student.
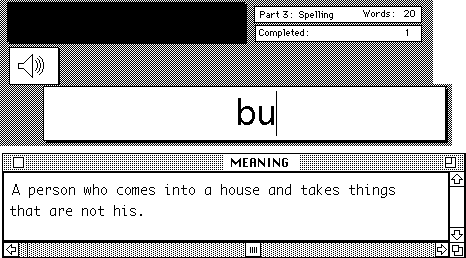
The control version of PET·200 is as follows. Part 1 gives the student a single complete-sentence example to help him choose the short definition, rather than a concordance, as shown in Figure 9.8. The sentence is merely the first line of concordance for the word, delivered as a complete sentence rather than a chopped-off line. After Part 1, when the correct definition has been chosen, all subsequent activities use the definition as the main information for choosing or constructing answers. Figure 9.9 shows a student trying to spell "burglar" with a definition where the concordance would have been.
As a reminder, Figure 9.10 shows the same task for the word "charge" using the experimental concordance version. In the control version, students never see a concordance, just the definition that they see in Part 1 of either version, plus a single example sentence. So the only difference between the versions is concordance yes or no, which of course could entail a further difference in amount of effort expended reading.

In the pilot run of PET·200, the two versions ran on alternate weeks (week 1 definitions, week 2 concordances, and so on). In this arrangement, the same people used both versions of the system. At the end of 12 weeks, six weeks of definitions work could be compared to six weeks of concordancing, and any concordancing effect could be isolated.
On the spelling task, the two versions produced no differences in weekly quiz scores. This can be seen in Figure 9.6 above, where there is no regular week-on week-off zig-zag in the top line, as there would be if viewing a concordance had any effect on learning the spellings. But the two versions produced significant differences in both scores on the text task of the quizzes and on amount of program use.
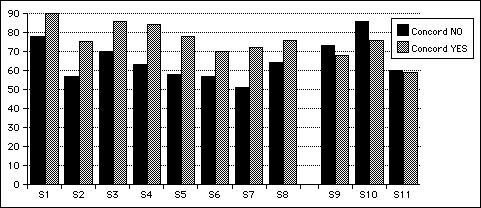
The block of 68% of correct answers on the text task was subdivided according to whether the definitions or concordance version of the program had been used in a particular week. Without concordance, students produced 228 correct out of 357 possible answers, or 63.9%. With concordance, they produced 194 correct out of 264 possible, or 75.9%, a mean concordance effect of 12% as shown in Table 9.1.
Concord NO |
Concord YES | |
|---|---|---|
| Wk1 40.9 | Wk2 78.2 | |
| Wk3 75.8 | Wk4 78.8 | |
| Wk5 65 | Wk6 74.5 | |
| Wk7 61 | Wk8 65 | |
| Wk9 83 | Wk10 72.7 | |
| Wk11 56.8 | Wk12 86.4 | |
| Mean | 63.9% |
75.9% |
| S. Dev. | 14.8 | 7.1 |
The difference between means was greater than chance (t = 1.8, p<.05) A graphic representation of the week-by-week data in Figure 9.11 emphasizes the small but persistent concordance effect (although with one reversal).

Viewed in terms of individuals, this information assumes a similar shape. Eight of 11 students in the remedial class averaged higher scores on the text task over 12 weeks when using the concordance version:
|
Concord NO |
Concord YES |
|---|---|---|
| S1 | 78 | 90 |
| S2 | 57 | 75.5 |
| S3 | 70 | 86 |
| S4 | 63 | 84 |
| S5 | 58 | 78 |
| S6 | 57 | 70 |
| S7 | 51 | 72 |
| S8 | 64 | 76 |
| S9 | 73 | 68 |
| S10 | 86 | 76 |
| S11 | 60 | 59 |
Mean |
65.2 |
75.9 |
| S. Dev. | 10.5 | 8.7 |
The mean scores are 65.2% without concordance, 75.9% with, a significant mean concordance effect of just under 11% (t= 2.59, p<.05). Figure 9.12 shows this information in graphic form. The graph shows that 8 of the 11 students (73%) were substantially aided by the concordance information. The 3 students out of 11 (27%) who did better without concordance nonetheless did well enough with it.
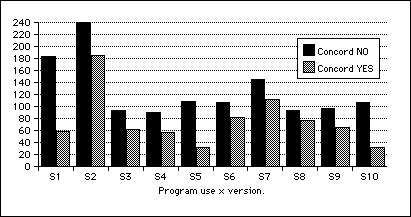
The two versions of PET·200 also produced significant differences in amount of program use. Unexpectedly, when amount of student interaction with PET·200 was plotted against program version, it was revealed that students consistently interacted less with the tutorial (answered fewer questions etc) when concordance was the information source-a lot less, close to half. Table 9.13 shows the kilobyte sizes.
|
Concord NO |
Concord YES |
|---|---|---|
| S1 | 184K | 59K |
| S2 | 240 | 185 |
| S3 | 94 | 62 |
| S4 | 90 | 56 |
| S5 | 109 | 31 |
| S6 | 106 | 82 |
| S7 | 145 | 112 |
| S8 | 93 | 76 |
| S9 | 96 | 65 |
| S10 | 107 | 32 |
Mean |
126.4K |
76K |
| S. Dev. | 49.5 | 44.9 |
The difference in means is greater than chance (t = 2.38, p<.05). Figure 9.13 represents the same information graphically.
Putting it all together, with a concordance available students seem to learn words 10% better using the system half as much.
Why? It is tempting to think that fewer clicks and keystrokes means more time spent reading concordances, contemplating multicontextuality, integrating meanings, etc. This might be the case if students were spending equal time on both versions of the program. In fact, this appears to be the case. The dribble file time logs reveal that students spent an average of ten hours using PET·200; the 600 minutes broke down into 309.6 minutes on the no-concordance version and 260.4 minutes on the concordance version, a difference no greater than chance (t = 1.36, p>.05). So between equal time and unequal activity there seems to be a space for more reading, which in turn ties to better word learning.
Even lower-intermediate learners seem able to pay attention to a concordance and can get useful information from it. Concordance information has no effect on knowledge of a word's spelling, which is non-semantic, but does have an effect on whether the word can be used in a novel context. So it appears that the multi-contextuality offered by several lines of concordance for the same word has the effect of producing transferable word knowledge-in Sternberg's (1987) phrase, multi-contextualization produces decontextualization, or transferability. This is an initial indication that there is a basis for developing a fully fledged corpus-based tutor that would test the concordance effect on a larger task.
The information gleaned from the development and evaluation of PET·200 will be fed into a full-scale corpus-based tutorial, which will increase the learning load from 240 words per term to 2400.
| contents |